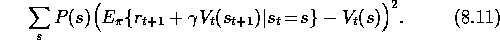We return now to the prediction case to take a closer look at the interaction
between bootstrapping, function approximation, and the on-policy distribution.
By bootstrapping we mean the updating of a value estimate on the basis of
other value estimates. TD methods involve bootstrapping, as do DP
methods, whereas Monte Carlo methods do not. TD( )
is a bootstrapping
method for
)
is a bootstrapping
method for 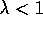 , and by convention we consider it to not be a
bootstrapping method for
, and by convention we consider it to not be a
bootstrapping method for  . Although TD(1) involves bootstrapping within an
episode, the net effect over a complete episode is the same as a
non-bootstrapping Monte Carlo update.
. Although TD(1) involves bootstrapping within an
episode, the net effect over a complete episode is the same as a
non-bootstrapping Monte Carlo update.
Bootstrapping methods are more difficult to combine with function approximation
methods than non-bootstrapping methods. For example, consider the case of value
value prediction with linear, gradient-descent function approximation.
In this case, non-bootstrapping methods find minimal MSE (8.1) solutions
for any distribution of training examples, P, whereas bootstrapping methods find
only near minimal MSE (8.9) solutions, and only for the on-policy
distribution. Moreover, the quality of the MSE bound for TD(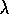 )
gets worse the
farther
)
gets worse the
farther 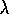 strays from 1, i.e., the farther the method moves from its
non-bootstrapping form.
strays from 1, i.e., the farther the method moves from its
non-bootstrapping form.
The restriction of the convergence results for bootstrapping methods to the on-policy distribution is of greatest concern. This is not a problem for on-policy methods such as Sarsa and actor-critic methods, but it is for off-policy methods such as Q-learning and DP methods. Off-policy control methods do not backup states (or state-action pairs) with exactly the same distribution with which the states would be encountered following the estimation policy (the policy whose value function they are estimating). Many DP methods, for example, backup all states uniformly. Q-learning may backup states according to an arbitrary distribution, but typically it backs them up according to the distribution generated by interacting with the environment and following a soft policy close to a greedy estimation policy. We use the term off-policy bootstrapping for any kind of bootstrapping using a distribution of backups different from the on-policy distribution. Surprisingly, off-policy bootstrapping combined with function approximation can lead to divergence and infinite MSE.
Example  .
. Baird's Counterexample.
Consider the six-state, episodic Markov process shown in
Figure 8.12. Episodes begin in one of the five upper states,
proceed immediately to the lower state, and then cycle there for some number of
steps before terminating. The reward is zero on all transitions, so the
true value function is
Baird's Counterexample.
Consider the six-state, episodic Markov process shown in
Figure 8.12. Episodes begin in one of the five upper states,
proceed immediately to the lower state, and then cycle there for some number of
steps before terminating. The reward is zero on all transitions, so the
true value function is 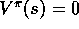 , for all s. The form of the approximate
value function is shown by the equations inset in each state. Note that the
overall function is linear and that there are fewer states than components of
, for all s. The form of the approximate
value function is shown by the equations inset in each state. Note that the
overall function is linear and that there are fewer states than components of
 . Moreover, the set of feature vectors,
. Moreover, the set of feature vectors,
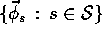 corresponding to this function form a linearly
independent set, and the true value function is easily formed by setting
corresponding to this function form a linearly
independent set, and the true value function is easily formed by setting
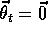 . In all ways, this task seems a favorable case for linear
function approximation.
. In all ways, this task seems a favorable case for linear
function approximation.
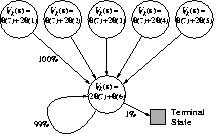
Figure 8.12: Baird's counterexample. The approximate value function for this Markov
process is of the form shown by the linear expressions inside each state. The
reward is always zero.
The prediction method we apply to this task is a linear,
gradient-descent form of DP policy evaluation. The parameter vector, 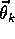 , is
updated in sweeps through the state space, performing a synchronous,
gradient-descent backup at every state, s, using the DP (full backup) target:
, is
updated in sweeps through the state space, performing a synchronous,
gradient-descent backup at every state, s, using the DP (full backup) target:
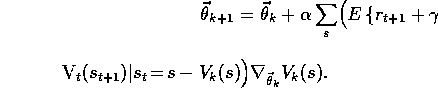
Like most DP methods, this one uses a uniform backup distribution, one of the
simplest off-policy distributions. Otherwise this is an ideal case. There is no
randomness and no asynchrony. Each state is updated exactly once per sweep
according to a classical DP backup. The method is entirely conventional except in
its use of a gradient-descent function approximator. Yet for some initial values
of the parameters, the system becomes unstable, as shown computationally in
Figure 8.13.
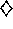
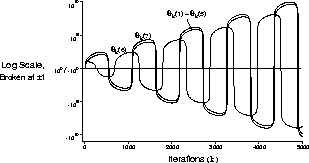
Figure 8.13: Computational demonstration of the instability of DP value prediction
with a linear function approximator on Baird's counterexample. The parameters
were  ,
, 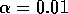 , and
, and  .
.
If we alter just the distribution of DP backups in Baird's counterexample, from
the uniform distribution to the on-policy distribution (which generally requires
asynchronous updating), then convergence is guaranteed to a solution with error
bounded by (8.9) for 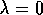 . This example is striking because the
DP method used is arguably the simplest and best understood bootstrapping
method, and the linear, gradient-descent method used is arguably the
simplest and best understood function approximator. The example shows
that even the simplest combination of bootstrapping and function approximation
can be unstable if the backups are not done according to the on-policy
distribution.
. This example is striking because the
DP method used is arguably the simplest and best understood bootstrapping
method, and the linear, gradient-descent method used is arguably the
simplest and best understood function approximator. The example shows
that even the simplest combination of bootstrapping and function approximation
can be unstable if the backups are not done according to the on-policy
distribution.
Counterexamples similar to Baird's also exist showing divergence for
Q-learning. This is cause for concern because otherwise Q-learning has
the best convergence guarantees of all control methods. Considerable effort has
gone into trying to find a remedy to this problem or to obtain some weaker, but still
workable, guarantee. For example, it may be possible to guarantee convergence of
Q-learning as long as the behavior policy (the policy used to select actions) is
sufficiently close to the estimation policy (the policy used in GPI), e.g., when
it is the  -greedy policy. To the best of our knowledge, Q-learning has never
been found to diverge in this case, but there has been no theoretical analysis.
In the rest of this section we present several of the other ideas that have been
explored.
-greedy policy. To the best of our knowledge, Q-learning has never
been found to diverge in this case, but there has been no theoretical analysis.
In the rest of this section we present several of the other ideas that have been
explored.
Suppose that instead of taking just a step toward
the expected one-step return on each iteration, as in Baird's
counterexample, we actually change the value function all the way to the best, least-squares
approximation. Would this solve the instability problem? Of course it would
if the feature vectors,  , formed a linearly independent
set, as they do in Baird's counterexample, because then exact approximation is
possible on each iteration and the method reduces to standard tabular DP.
But of course the point here is to consider the case when an exact solution
is not possible. In this case stability is not
guaranteed even when forming the best approximation at each iteration, as shown
by the following example.
, formed a linearly independent
set, as they do in Baird's counterexample, because then exact approximation is
possible on each iteration and the method reduces to standard tabular DP.
But of course the point here is to consider the case when an exact solution
is not possible. In this case stability is not
guaranteed even when forming the best approximation at each iteration, as shown
by the following example.

Figure 8.14: Tsitsiklis and Van Roy's counterexample to DP policy evaluation
with least-squares linear function approximation.
Example  .
. Tsitsiklis and Van Roy's Counterexample.
The simplest counterexample to linear least-squares DP is shown in
Figure 8.14. There are just
two nonterminal states, and the modifiable parameter
Tsitsiklis and Van Roy's Counterexample.
The simplest counterexample to linear least-squares DP is shown in
Figure 8.14. There are just
two nonterminal states, and the modifiable parameter 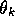 is a scalar. The
estimated value of the first state is just
is a scalar. The
estimated value of the first state is just 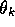 , and the estimated value of
the second state is
, and the estimated value of
the second state is 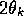 . The reward is zero on all transitions, so the
true values are zero at both states, which is exactly representable with
. The reward is zero on all transitions, so the
true values are zero at both states, which is exactly representable with
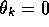 . If we set
. If we set  at each step so as to minimize the MSE
between the estimated value and the expected one-step return, then we have
at each step so as to minimize the MSE
between the estimated value and the expected one-step return, then we have
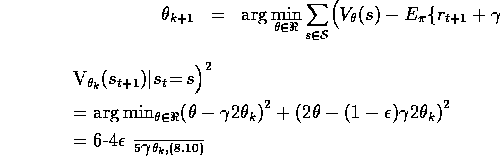
where 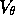 denotes the value function given
denotes the value function given 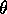 . The sequence
. The sequence
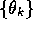 diverges when
diverges when 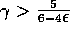 and
and 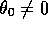 .
.
One way to try to prevent instability is to use special kinds of function approximators. In particular, stability is guaranteed for function approximators that do not extrapolate from the observed targets. These methods, called averagers, include nearest neighbor methods and local weighted regression, but not popular methods such as tile coding and backpropagation.
Another approach is to attempt to minimize not the squared error from the true value function, but the squared error from the expected one step return. It is natural to call this error measure the mean squared Bellman error:
This suggests the gradient-descent procedure:

where the expected values are implicitly conditional on 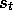 .
This update is guaranteed to converge to
minimize the expected Bellman error. However, this method is feasible only for
deterministic systems or when a model is available. The problem is that the
update above involves the next state,
.
This update is guaranteed to converge to
minimize the expected Bellman error. However, this method is feasible only for
deterministic systems or when a model is available. The problem is that the
update above involves the next state,
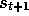 , appearing in two expected values that are multiplied
together. To get an unbiased sample of the product one needs two
independent samples of the next state, but during normal interaction with the
environment only one is obtained. Because of this, the method is probably
limited in practice to cases in which a model is available (to produce a second
sample). In practice, this method is also sometimes slow to converge. To handle
that problem, Baird (1995) has proposed combining this method parametrically with
conventional TD methods.
, appearing in two expected values that are multiplied
together. To get an unbiased sample of the product one needs two
independent samples of the next state, but during normal interaction with the
environment only one is obtained. Because of this, the method is probably
limited in practice to cases in which a model is available (to produce a second
sample). In practice, this method is also sometimes slow to converge. To handle
that problem, Baird (1995) has proposed combining this method parametrically with
conventional TD methods.
Exercise  .
. (programming)
(programming)
Look up the paper by Baird (1995) on the internet and obtain his counterexample for Q-learning. Implement it and demonstrated the divergence.