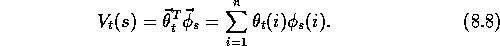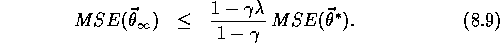One of the most important special cases in gradient-descent function
approximation is that in which the approximate function, 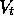 , is a
linear function of the parameter vector,
, is a
linear function of the parameter vector, 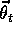 . Corresponding to every
state, s, there is a column vector of features,
. Corresponding to every
state, s, there is a column vector of features,  , with the same number of components as
, with the same number of components as 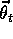 .
The features may be constructed from the states in many different
ways; we cover a few possibilities below. However the features are constructed,
the approximate state-value function is given by
.
The features may be constructed from the states in many different
ways; we cover a few possibilities below. However the features are constructed,
the approximate state-value function is given by
In this case the approximate value function is said to be linear in the parameters, or simply linear.
It is natural to use gradient-descent
updates with linear function approximators. The
gradient of the approximate value function with respect to 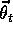 in this
case is just
in this
case is just

Thus, the general gradient-descent update (8.3) reduces to a
particularly simple form in the linear case. In addition, in the linear case
there is only one optimum  (or, in degenerate cases, one set of
equally good optima). Thus, any method guaranteed to converges to or near a
local optimum is automatically guaranteed to converge to or near the global
optimum. Because they are simple in these ways, linear gradient-descent
function approximators are the most favorable for mathematical analysis.
Almost all useful convergence results for learning systems of all kinds are
for linear (or simpler) function approximators.
(or, in degenerate cases, one set of
equally good optima). Thus, any method guaranteed to converges to or near a
local optimum is automatically guaranteed to converge to or near the global
optimum. Because they are simple in these ways, linear gradient-descent
function approximators are the most favorable for mathematical analysis.
Almost all useful convergence results for learning systems of all kinds are
for linear (or simpler) function approximators.
In particular, the gradient-descent TD(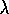 )
algorithm discussed in the previous
section (Figure 8.1) has been proven to converge in the linear case if
the step-size parameter is reduced over time according to the usual conditions
(2 .7
).
Convergence is not to the
minimum-error parameter vector,
)
algorithm discussed in the previous
section (Figure 8.1) has been proven to converge in the linear case if
the step-size parameter is reduced over time according to the usual conditions
(2 .7
).
Convergence is not to the
minimum-error parameter vector,
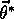 , but to a nearby parameter vector,
, but to a nearby parameter vector,  , whose error is bounded
according to:
, whose error is bounded
according to:
That is, the asymptotic error is no more than 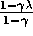 times the smallest possible error. As
times the smallest possible error. As 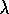 approaches 1, the bound
approaches the minimum error. An analogous bound
applies to other on-policy bootstrapping methods. For
example, linear gradient-descent DP backups, using (8.3), with the
on-policy distribution, will converge to the same result as TD(0).
Technically, this bound applies only to discounted continual tasks, but a related
result presumably holds for episodic tasks. There are also a few technical
conditions on the rewards, features, and decrease in the step-size parameter,
which we are omitting here. The full details can be found in the original paper
(Tsitsiklis and Van Roy, 1997).
approaches 1, the bound
approaches the minimum error. An analogous bound
applies to other on-policy bootstrapping methods. For
example, linear gradient-descent DP backups, using (8.3), with the
on-policy distribution, will converge to the same result as TD(0).
Technically, this bound applies only to discounted continual tasks, but a related
result presumably holds for episodic tasks. There are also a few technical
conditions on the rewards, features, and decrease in the step-size parameter,
which we are omitting here. The full details can be found in the original paper
(Tsitsiklis and Van Roy, 1997).
Critical to the above result is that states are backed up according to the on-policy distribution. For other backup distributions, bootstrapping methods using function approximation may actually diverge to infinity. Examples of this and a discussion of possible solution methods are given in Section 8.5
Beyond these theoretical results, linear learning methods are also of interest because in practice they can be very efficient both in terms of data and computation. Whether or not this is so depends critically on how the states are represented in terms of the features. Choosing features appropriate to the task is an important way of adding prior domain knowledge to reinforcement learning systems. Intuitively, the features should correspond to the natural features of the task, those along which generalization is most appropriate. If we are valuing geometric objects, for example, we might want to have features for each possible shape, color, size, or function. If we are valuing states of a mobile robot, then we might want to have features for locations, degrees of remaining battery power, recent sonar readings, etc.
In general, we also need features for combinations of these natural qualities. This is because the linear form prohibits the representation of interactions between features, such as the presence of feature i being good only in the absence of feature j. For example, in the pole-balancing task (Example 3.4), a high angular velocity may be either good or bad depending on the angular position. If the angle is high, then high angular velocity means an imminent danger of falling, a bad state, whereas if the angle is low, then high angular velocity means the pole is righting itself, a good state. In cases with such interactions one needs to introduce features for particular conjunctions of feature values when using a linear function approximator. We next consider some general ways of doing this.
Exercise  .
.
How could we reproduce the tabular case within the linear framework?
Exercise  .
.
How could we reproduce the state aggregation case (see Exercise 8.4 ) within the linear framework?