


Tile coding is a form of coarse coding that is particularly well suited for use on sequential digital computers and for efficient online learning. In tile coding the receptive fields of the features are grouped into exhaustive partitions of input space. Each such partition is called a tiling, and each element of the partition is called a tile. Each tile is a the receptive field for one binary feature.
An immediate advantage of tile coding is that the overall number of
features that are present at one time is strictly controlled and independent
of the input state. Exactly one feature is present in each tiling, thus the
total number of features present is always the same as the number of
tilings. Together with the level of response being set at 1, this allows
the step-size parameter, 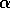 , to be set in an easy, intuitive way. For example,
choosing
, to be set in an easy, intuitive way. For example,
choosing 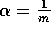 , where
m is the number of tilings, results in exact one-trial learning. If the
example
, where
m is the number of tilings, results in exact one-trial learning. If the
example 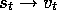 is received, then whatever the prior value,
is received, then whatever the prior value, 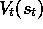 ,
the new value will be
,
the new value will be 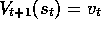 . Usually one wishes to change
more slowly than this, to allow for generalization and stochastic variation
in target outputs. For example, one might choose
. Usually one wishes to change
more slowly than this, to allow for generalization and stochastic variation
in target outputs. For example, one might choose
 , in which case one would move one-tenth of
the way to the target in one update.
, in which case one would move one-tenth of
the way to the target in one update.
Because tile coding uses exclusively binary (0-1 valued) features, the weighted
sum making up the approximate value function (8.8) is almost trivial
to compute. Rather than performing n multiplications and additions, one simply
computes the indices of the
m<<n present features and then adds up the m corresponding components of
the parameter vector. The eligibility-trace computation (8.7) is
also simplified because the components of the gradient,
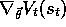 , are also usually 0, and otherwise 1.
, are also usually 0, and otherwise 1.
The computation of the indices of the present features is particularly easy if grid-like tilings are used. The ideas and techniques here are best illustrated by examples. Suppose we address a task with two continuous state variables. Then the simplest way to tile the space is with a uniform two-dimensional grid:

Given the x and y coordinates of a point in the space, it is
computationally easy to determine the index of the tile it is in. When multiple
tilings are used. each is offset by a different amount, so that each cuts
the space in a different way. In the example shown in
Figure 8.5, an extra row and column of tiles have been added to
the grid so that no points are left uncovered. The two tiles highlighted
are those that present in the state indicated by the `` ." The
different tilings may be offset by random amounts, or by cleverly designed
deterministic strategies (simply offsetting each dimension by the same
increment is known not to be a good idea). The effects on generalization
and asymptotic accuracy illustrated in Figures 8.3 and
8.4 apply here as well. The width and shape of the tiles
should be chosen to match the width of generalization that one expects to be
appropriate. The number of tilings should be chosen to influence the
density of tiles. The denser the tiling, the finer and more accurately the
desired function can be approximated, but the greater the computational
costs.
." The
different tilings may be offset by random amounts, or by cleverly designed
deterministic strategies (simply offsetting each dimension by the same
increment is known not to be a good idea). The effects on generalization
and asymptotic accuracy illustrated in Figures 8.3 and
8.4 apply here as well. The width and shape of the tiles
should be chosen to match the width of generalization that one expects to be
appropriate. The number of tilings should be chosen to influence the
density of tiles. The denser the tiling, the finer and more accurately the
desired function can be approximated, but the greater the computational
costs.

Figure 8.5: Multiple, overlapping grid-tilings.
It is important to note that the tilings can be arbitrary and need not be uniform grids. Not only can the tiles be strangely shaped, as in Figure 8.6a, but they can be shaped and distributed to give particular kinds of generalization. For example, the stripe tiling in Figure 8.6b will promote generalization along the vertical dimension and discrimination along the horizontal dimension, particularly on the left. The diagonal stripe tiling in Figure 8.6c will promote generalization along one diagonal. In higher dimensions, axis-aligned stripes correspond to ignoring some of the dimensions in some of the tilings, i.e., to hyperplanar slices.
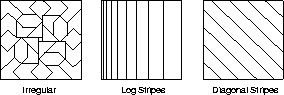
Figure 8.6: A variety of tilings.
Another important trick for reducing memory requirements is hashing---a consistent pseudo-random collapsing of a large tiling into a much smaller set of tiles. Hashing produces tiles consisting of non-contiguous, disjoint regions randomly spread throughout the state space, but which still form an exhaustive tiling. For example, one tile might consist of the four sub-tiles shown below:

Through hashing, memory requirements are often reduced by large factors with little loss of performance. This is possible because high resolution is needed in only a small fraction of the state space. Hashing frees us from the curse of dimensionality in the sense that memory requirements need not be exponential in the number of dimensions, but need merely match the real demands of the task. Good public-domain implementations of tile coding, including hashing, are widely available.
Exercise  .
.
Suppose we believe that one of two state dimensions is more likely to have an effect on the value function than the other, that generalization should be primarily across this dimension rather than along it. What kind of tilings could be used to take advantage of this prior knowledge?