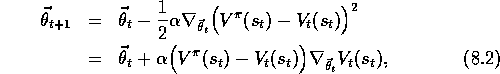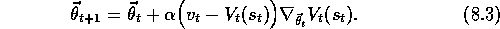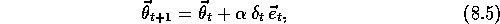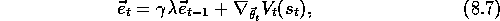We now develop in detail one class of learning methods for function approximation in value prediction, those based on gradient descent. Gradient-descent methods are among the most widely used of all function approximation methods and are particularly well-suited to reinforcement learning.
In gradient-descent methods, the parameter vector is a column vector with
a fixed number of real valued components,
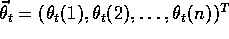 (the `T' here denotes
transpose), and
(the `T' here denotes
transpose), and 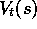 is a smooth differentiable function of
is a smooth differentiable function of
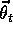 for all
for all 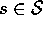 . For now, let us assume that on each step, t, we
observe a new example
. For now, let us assume that on each step, t, we
observe a new example 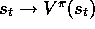 . These states might be
successive states from an interaction with the environment, but for now we do
not assume so. Even though we are given the exact,
correct values,
. These states might be
successive states from an interaction with the environment, but for now we do
not assume so. Even though we are given the exact,
correct values, 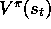 for each
for each 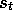 , there is still a difficult problem
because our function approximator has limited resources and thus limited
resolution. In particular, there is generally no
, there is still a difficult problem
because our function approximator has limited resources and thus limited
resolution. In particular, there is generally no 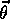 that gets all the states,
or even all the examples, exactly correct. In addition, we must generalize to
all the other states that have not appeared in examples.
that gets all the states,
or even all the examples, exactly correct. In addition, we must generalize to
all the other states that have not appeared in examples.
We assume that states appear in examples with the same distribution, P, over which we are trying to minimize the MSE as given by (8.1). A good strategy in this case is to try to minimize error on the observed examples. Gradient-descent methods do this by adjusting the parameter vector after each example by a small amount in the direction that would most reduce the error on that example:
where 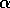 is a positive step-size parameter, and
is a positive step-size parameter, and 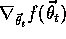 ,
for any function, f,
denotes the vector of partial derivatives,
,
for any function, f,
denotes the vector of partial derivatives, 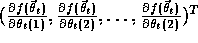 . This
derivative vector is the gradient of f with respect to
. This
derivative vector is the gradient of f with respect to 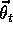 .
This kind of method is called gradient descent because the overall step
in
.
This kind of method is called gradient descent because the overall step
in 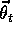 is proportional to the negative gradient of the example's squared
error. This is the direction in which the error falls most rapidly.
is proportional to the negative gradient of the example's squared
error. This is the direction in which the error falls most rapidly.
It may not be immediately apparent why only a small step is taken in the direction of the gradient. Could we not move all the way in this direction and completely eliminate the error on the example? In many cases this could be done, but usually it is not desirable. Remember that we do not seek or expect to find a value function that has zero error on all states, but only an approximation that balances the errors in different states. If we completely corrected each example in one step, then we would not find such a balance. In fact, the convergence results for gradient methods assume that the step-size parameter decreases over time. If it decreases in such a way as to satisfy the standard stochastic-approximation conditions (2 .7 ), then the gradient-descent method (8.2) is guaranteed to converge to a local optimum.
We turn now to the case in which the output, 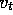 , of the tth
training example,
, of the tth
training example, 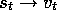 , is not the true value,
, is not the true value,
 , but some approximation of it. For example,
, but some approximation of it. For example, 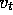 might be a
noise-corrupted version of
might be a
noise-corrupted version of 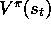 , or it might be one of the backed-up
values mentioned in the previous section. In such cases we cannot perform the
exact update (8.2) because
, or it might be one of the backed-up
values mentioned in the previous section. In such cases we cannot perform the
exact update (8.2) because 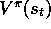 is unknown, but we can
approximate it by substituting
is unknown, but we can
approximate it by substituting 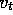 in place of
in place of 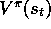 . This yields
the general gradient-descent method for state-value prediction:
. This yields
the general gradient-descent method for state-value prediction:
If 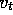 is an unbiased estimate, i.e., if
is an unbiased estimate, i.e., if 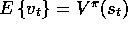 , for
each t, then
, for
each t, then  is guaranteed to converge to a local optimum under the
usual stochastic approximation conditions (2 .7
) for decreasing
the step-size parameter,
is guaranteed to converge to a local optimum under the
usual stochastic approximation conditions (2 .7
) for decreasing
the step-size parameter, 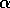 .
.
For example, suppose the states in the examples are the states generated
by interaction (or simulated interaction) with the environment using policy  .
Let
.
Let  denote the return following each state,
denote the return following each state, 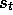 . Because the true value
of a state is the expected value of the return following it, the Monte Carlo
target
. Because the true value
of a state is the expected value of the return following it, the Monte Carlo
target
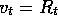 is by definition an unbiased estimate of
is by definition an unbiased estimate of 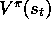 . With this
choice, the general gradient-descent method (8.3) converges to a
locally-optimal approximation to
. With this
choice, the general gradient-descent method (8.3) converges to a
locally-optimal approximation to 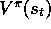 . Thus, the gradient-descent
version of Monte Carlo state-value prediction is guaranteed to find a
locally-optimal solution.
. Thus, the gradient-descent
version of Monte Carlo state-value prediction is guaranteed to find a
locally-optimal solution.
Similarly, we can use n
-step TD returns and their averages for 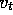 . For
example, the gradient-descent form of TD(
. For
example, the gradient-descent form of TD(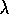 )
uses the
)
uses the 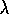 -return,
-return,
 , as its approximation to
, as its approximation to  , yielding the
forward-view update:
, yielding the
forward-view update:
Unfortunately, for 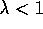 ,
, 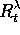 is not an unbiased estimate of
is not an unbiased estimate of
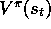 , and thus this method does not converge to a local optimum. The
situation is the same when DP targets are used such as
, and thus this method does not converge to a local optimum. The
situation is the same when DP targets are used such as
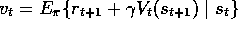 . Nevertheless, such bootstrapping methods can be quite
effective, and other performance guarantees are available for important special
cases, as we discuss later in this chapter. For now we emphasize the
relationship of these methods to the general gradient-descent form
(8.3). Although, increments as in (8.4) are not
themselves gradients, it is useful to view this method
as a gradient-descent method (8.3) with a bootstrapping
approximation in place of the desired output,
. Nevertheless, such bootstrapping methods can be quite
effective, and other performance guarantees are available for important special
cases, as we discuss later in this chapter. For now we emphasize the
relationship of these methods to the general gradient-descent form
(8.3). Although, increments as in (8.4) are not
themselves gradients, it is useful to view this method
as a gradient-descent method (8.3) with a bootstrapping
approximation in place of the desired output,  .
.
Just as (8.4) provides the forward view of
gradient-descent TD( )
, the backwards view is provided by
)
, the backwards view is provided by
where  is the usual TD error,
is the usual TD error,
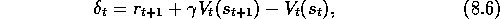
and
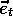 is a column vector of eligibility traces, one
for each component of
is a column vector of eligibility traces, one
for each component of  , updated by
, updated by
with  . A complete algorithm for online gradient-descent TD(
. A complete algorithm for online gradient-descent TD( )
is
given in Figure 8.1.
)
is
given in Figure 8.1.
Initializearbitrarily and
Repeat (for each episode):
Repeat (for each step of episode):
Take action a, observe reward, r, and next state,
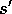
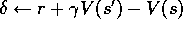

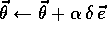
until s is terminal
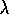 )
for estimating
)
for estimating  . The approximate
value function, V, is implicitly a function of
. The approximate
value function, V, is implicitly a function of 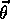 .
.
Two forms of gradient-based function approximators have been used widely in reinforcement learning. One is multi-layer artificial neural networks using the error backpropagation algorithm. This maps immediately onto the equations and algorithms just given, where the backpropagation process is the way of computing the gradients. The second popular form is the linear form, which we discuss extensively in the next section.
Exercise 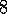 .
.
Show that table-lookup TD(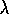 )
is a special case of
general TD(
)
is a special case of
general TD(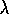 )
as given by equations (8.5--8.7).
)
as given by equations (8.5--8.7).
Exercise 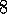 .
.
State aggregation is a simple form of generalizing function approximator in which states are grouped together, with one table entry (value estimate) used for each group. Whenever a state in a group is encountered, the group's entry is used to determine the state's value, and when the state is updated, the group's entry is updated. Show that this kind of state aggregation is a special case of a gradient method such as (8.4).
Exercise 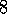 .
.
The equations given in this section are for the online version
of gradient-descent TD(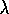 )
. What are the equations for the offline
version? Give a complete description specifying the new approximate value
function at the end of an episode,
)
. What are the equations for the offline
version? Give a complete description specifying the new approximate value
function at the end of an episode, 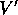 , in terms of the approximate value
function used during the episode, V. Start by modifying a forward-view
equation for TD(
, in terms of the approximate value
function used during the episode, V. Start by modifying a forward-view
equation for TD(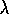 )
, such as (8.4).
)
, such as (8.4).
Exercise  .
.
For offline updating, show that equations (8.5--8.7) produce updates identical to (8.4).