


In the maze example presented in the previous section, the changes in the model were relatively modest. The model started out empty, and was then filled only with exactly correct information. In general, we can not expect to be so fortunate. Models may be incorrect because the environment is stochastic and only a limited number of samples have been observed, because the model was learned using function approximation that has generalized imperfectly, or simply because the environment has changed and its new behavior has not yet been observed. When the model is incorrect the planning process will compute a suboptimal policy.
In some cases, the suboptimal policy computed by planning quickly leads to the discovery and correction of the modeling error. This tends to happen when the model is optimistic in the sense of predicting greater reward or better state transitions than are actually possible. The planned policy attempts to exploit these opportunities and in so doing discovers that they do not exist.
Example  .
. Blocking Maze.
A maze example illustrating this relatively minor kind of modeling error and
recovery from it is shown in Figure 9.7. Initially, there is a
short path from start to goal, to the right of the barrier, as shown in the upper
left of the figure. After 1000 time steps, the short path is ``blocked," and a
longer path is opened up along the left-hand side of the barrier, as shown in upper
right of the figure. The graph shows average cumulative reward for Dyna-Q and two
other Dyna agents. The first part of the graph shows that all three Dyna
agents found the short path within 1000 steps. When the environment changed, the
graphs become flat, indicating a period during which the agents obtained no reward
because they were wandering around behind the barrier. After a while, however,
they were able to find the new opening and the new optimal behavior.
Blocking Maze.
A maze example illustrating this relatively minor kind of modeling error and
recovery from it is shown in Figure 9.7. Initially, there is a
short path from start to goal, to the right of the barrier, as shown in the upper
left of the figure. After 1000 time steps, the short path is ``blocked," and a
longer path is opened up along the left-hand side of the barrier, as shown in upper
right of the figure. The graph shows average cumulative reward for Dyna-Q and two
other Dyna agents. The first part of the graph shows that all three Dyna
agents found the short path within 1000 steps. When the environment changed, the
graphs become flat, indicating a period during which the agents obtained no reward
because they were wandering around behind the barrier. After a while, however,
they were able to find the new opening and the new optimal behavior.
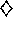
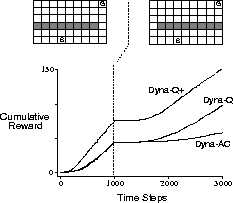
Figure 9.7: Average performance of Dyna agents on a Blocking task. The left
environment was used for the first 1000 steps, the right environment for the rest.
Dyna-Q+ is Dyna-Q with an exploration bonus that encourages exploration. Dyna-AC
is a Dyna agent that uses an actor-critic learning method instead of Q-learning.
Greater difficulties arise when the environment changes to become better than it was before, and yet the formerly correct policy does not reveal the improvement. In these cases the modeling error may not be detected for a very long time, if ever, as we see in the next example.
Example  .
. Shortcut Maze.
The problem caused by this kind of environmental change is illustrated by the maze
example shown in Figure 9.8. Initially, the optimal path is to go
around the left side of the barrier (upper left). After 3000 steps, however, a
shorter path is opened up along the right side, without disturbing the longer
path (upper right). The graph shows that two of the three Dyna agents never switch
to the shortcut. In fact, they never realize that it exists. Their models say
there is no shortcut, so the more they plan, the less likely they are to step to
the right and discover it. Even with an
Shortcut Maze.
The problem caused by this kind of environmental change is illustrated by the maze
example shown in Figure 9.8. Initially, the optimal path is to go
around the left side of the barrier (upper left). After 3000 steps, however, a
shorter path is opened up along the right side, without disturbing the longer
path (upper right). The graph shows that two of the three Dyna agents never switch
to the shortcut. In fact, they never realize that it exists. Their models say
there is no shortcut, so the more they plan, the less likely they are to step to
the right and discover it. Even with an  -greedy policy, it is very unlikely that
an agent will take so many exploratory actions that the shortcut will be
discovered.
-greedy policy, it is very unlikely that
an agent will take so many exploratory actions that the shortcut will be
discovered.
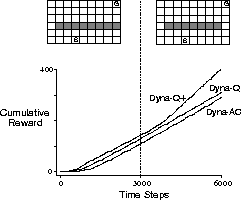
Figure 9.8: Average performance of Dyna agents on a Shortcut task. The left
environment was used for the first 3000 steps, the right environment for the
rest.
The general problem here is another version of the conflict between exploration and exploitation. In a planning context, exploration means trying actions that improve the model, whereas exploitation means behaving in the optimal way given the current model. We want the agent to explore to find changes in the environment, but not so much that performance is greatly degraded. Just as in the earlier exploitation/exploration conflict, there probably is no solution that is both perfect and practical, but simple heuristics are often effective.
The Dyna-Q+ agent that did solve the shortcut problem used one
such heuristic. This agent kept track for each state-action pair of how many time
steps had elapsed since the pair had last been tried in a real interaction with the
environment. The more time that has elapsed, the greater (we might presume) the
chance that the dynamics of this pair has changed and that the model of it is
incorrect. To encourage behavior that tests long-untried actions, a special
``bonus reward" was given on simulated experiences involving these actions. In
particular, if the modeled reward for a transition was r, and the transition had
not been tried in
n time steps, then planning backups were done as if that transition produced a
reward of
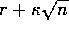 , for some small
, for some small  . This encouraged the agent
to keep testing all accessible state transitions and even to plan long sequences of
actions in order to carry out such tests. Of course all this testing has its cost,
but in many cases, as here, this kind of computational curiosity is well worth the
extra exploration.
. This encouraged the agent
to keep testing all accessible state transitions and even to plan long sequences of
actions in order to carry out such tests. Of course all this testing has its cost,
but in many cases, as here, this kind of computational curiosity is well worth the
extra exploration.
Exercise  .
.
Why does the Dyna agent with exploration bonus, Dyna-Q+, perform better in the first phase as well as in the second phase of the blocking and shortcut experiments?
Exercise  .
.
Careful inspection of Figure 9.8 reveals that the difference between Dyna-Q+ and Dyna-Q is narrowing slightly over the first part of the experiment. What is the reason for this?
Exercise  .
.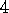 (programming)
(programming)
The exploration bonus described above actually changes the estimated values of
states and actions. Is this necessary? Suppose the bonus 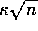 was used not in backups, but solely in action selection. That is, suppose the
action selected was always that for which
was used not in backups, but solely in action selection. That is, suppose the
action selected was always that for which 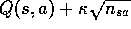 was
maximal. Carry out a gridworld experiment that tests and illustrates the strengths
and weaknesses of this alternate approach.
was
maximal. Carry out a gridworld experiment that tests and illustrates the strengths
and weaknesses of this alternate approach.