


At this point you may be wondering why we bother with bootstrapping methods at
all. Non-bootstrapping methods can be used with function approximation more
reliably and over a broader range of conditions than bootstrapping methods.
Non-bootstrapping methods achieve a lower asymptotic error than
bootstrapping methods, even when backups are done according to the on-policy
distribution. By using eligibility traces and 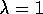 , it is even possible to
implement non-bootstrapping methods online, in a step-by-step incremental
manner. Despite all this, in practice bootstrapping methods are usually the
methods of choice.
, it is even possible to
implement non-bootstrapping methods online, in a step-by-step incremental
manner. Despite all this, in practice bootstrapping methods are usually the
methods of choice.
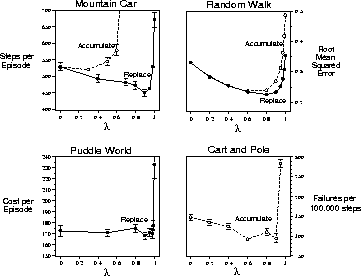
Figure: The effect of 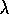 on reinforcement learning performance.
In all cases, the better the performance, the lower the curve. The
two left panels are applications to simple continuous-state control tasks
using the Sarsa(
on reinforcement learning performance.
In all cases, the better the performance, the lower the curve. The
two left panels are applications to simple continuous-state control tasks
using the Sarsa(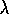 )
algorithm and tile coding, with either replacing or
accumulating traces (Sutton, 1996). The upper right
panel is for policy evaluation on a random-walk task using TD(
)
algorithm and tile coding, with either replacing or
accumulating traces (Sutton, 1996). The upper right
panel is for policy evaluation on a random-walk task using TD(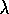 )
(Singh and
)
(Singh and
Sutton, 1996). The lower right panel is unpublished data for the
pole-balancing task (Example 3.4) from an earlier study (Sutton, 1984).
In empirical comparisons, bootstrapping methods usually perform much better
than non-bootstrapping methods. A convenient way to make such comparisons is to
use a TD method with eligibility traces and vary 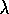 from 0 (pure bootstrapping)
to 1 (pure non-bootstrapping). Figure 8.15 summarizes a
collection of such results. In all cases, performance became much worse as
from 0 (pure bootstrapping)
to 1 (pure non-bootstrapping). Figure 8.15 summarizes a
collection of such results. In all cases, performance became much worse as 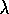 \
approached 1, the non-bootstrapping case. The example in the upper right of the
figure is particularly significant in this regard. This is a policy-evaluation
task and the performance measure used is root MSE (at the end of each trial,
averaged over the first 20 trials). Asymptotically, the
\
approached 1, the non-bootstrapping case. The example in the upper right of the
figure is particularly significant in this regard. This is a policy-evaluation
task and the performance measure used is root MSE (at the end of each trial,
averaged over the first 20 trials). Asymptotically, the
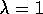 case must be best according to this measure, but here, short of the
asymptote, we see it performing much worse.
case must be best according to this measure, but here, short of the
asymptote, we see it performing much worse.
At this time it is unclear why methods that involve some bootstrapping perform so much better than pure non-bootstrapping methods. It could be just that bootstrapping methods learn faster, or it could be that they actually learn something better than non-bootstrapping methods. The available results indicate that non-bootstrapping methods are better than bootstrapping methods at reducing MSE from the true value function, but reducing MSE is not necessarily the most important goal. For example, if you add 1000 to the true action-value function at all state-action pairs, then it will have very poor MSE, but you will still get the optimal policy. Nothing quite that simple is going on with bootstrapping methods, but they do seem to do something right. We expect the understanding of these issues to improve as research continues.