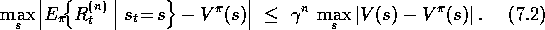What is the space of methods in between Monte Carlo and TD methods? Consider
estimating 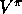 from sample episodes generated using
from sample episodes generated using  . Monte Carlo
methods perform a backup for each state based on the entire sequence of observed
rewards from that state until the end of the episode. The backup of simple TD
methods, on the other hand, is based on just the one next reward, using the value
of the state one step later as a proxy for the remaining rewards. One kind of
intermediate method, then, would perform a backup based on an intermediate number
of rewards: more than one, but less than all of them until termination. For
example, a 2-step backup would be based on the first two rewards and the estimated
value of the state two steps later. Similarly we could have 3-step backups,
4-step backups, etc. Figure 7.1 diagrams the spectrum of
n
-step backups for
. Monte Carlo
methods perform a backup for each state based on the entire sequence of observed
rewards from that state until the end of the episode. The backup of simple TD
methods, on the other hand, is based on just the one next reward, using the value
of the state one step later as a proxy for the remaining rewards. One kind of
intermediate method, then, would perform a backup based on an intermediate number
of rewards: more than one, but less than all of them until termination. For
example, a 2-step backup would be based on the first two rewards and the estimated
value of the state two steps later. Similarly we could have 3-step backups,
4-step backups, etc. Figure 7.1 diagrams the spectrum of
n
-step backups for 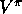 , with 1-step, simple TD backups on the left and
up-until-termination Monte Carlo backups on the right.
, with 1-step, simple TD backups on the left and
up-until-termination Monte Carlo backups on the right.
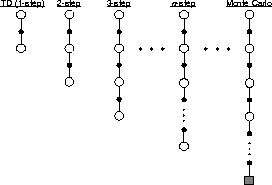
Figure 7.1: The spectrum ranging from the 1-step backups of
simple TD methods to the up-until-termination backups of Monte Carlo methods. In
between are the n
-step backups, based on n
steps of real rewards and the
estimated value of the n
th next state, all appropriately discounted.
The methods that use n -step backups are still TD methods because they still change an earlier estimate based on how it differs from a later estimate. Now the later estimate is not one step later, but n steps later. Methods in which the temporal difference extends over n steps are called n -step TD methods. The TD methods introduced in the previous chapter all use 1-step backups and we henceforth call them 1-step TD methods.
More formally, consider the backup
applied to state 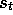 as a result of the state-reward sequence,
as a result of the state-reward sequence,
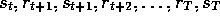 (omitting the actions for
simplicity). We know that in Monte Carlo backups the estimate
(omitting the actions for
simplicity). We know that in Monte Carlo backups the estimate 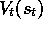 of
of
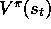 is updated in the direction of the complete return:
is updated in the direction of the complete return:
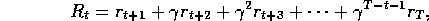
where T is the last time step of the episode. Let us call this quantity the target of the backup. Whereas in Monte Carlo backups the target is the expected return, in 1-step backups the target is the first reward plus the discounted estimated value of the next state:
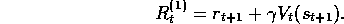
This makes sense because 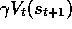 takes the place of the remaining terms
takes the place of the remaining terms
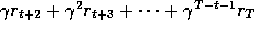 , as we discussed in the
previous chapter. Our point now is that this
idea makes just as much sense after two steps as it does after one. The 2-step
target is
, as we discussed in the
previous chapter. Our point now is that this
idea makes just as much sense after two steps as it does after one. The 2-step
target is
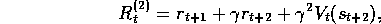
where now 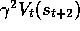 takes the place of the terms
takes the place of the terms 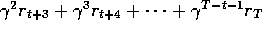 . In general, the n
-step target is
. In general, the n
-step target is
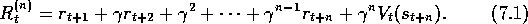
This quantity is sometimes called the ``corrected n
-step truncated return"
because it is a return truncated after n
steps and then approximately corrected
for the truncation by adding the estimated value of the n
th next state. That
terminology is very descriptive but a bit long. We instead refer to 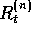 simply as the n
-step return at time t.
simply as the n
-step return at time t.
Of course, if the episode ends in less than n
steps, then the truncation
in an n
-step return occurs at the episode's end, resulting in the
conventional complete return. In other words, if T-t<n, then
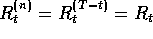 . Thus, the last n
n
-step returns of any episode
are always complete returns, and an infinite-step return is always a complete
return. This definition enables us to simply treat Monte Carlo methods as the
special case of infinite-step returns. All of this is consistent with the tricks
for treating episodic and continual tasks equivalently that we introduced in
Section 3.4. There we chose to treat the terminal state as a state that always
transitions to itself with zero reward. Under this trick, all n
-step returns
that last up to or past termination just happen to have the same value as the
complete return.
. Thus, the last n
n
-step returns of any episode
are always complete returns, and an infinite-step return is always a complete
return. This definition enables us to simply treat Monte Carlo methods as the
special case of infinite-step returns. All of this is consistent with the tricks
for treating episodic and continual tasks equivalently that we introduced in
Section 3.4. There we chose to treat the terminal state as a state that always
transitions to itself with zero reward. Under this trick, all n
-step returns
that last up to or past termination just happen to have the same value as the
complete return.
An n
-step backup is defined to be a backup towards the n
-step return. In
the tabular, state-value case, the increment to 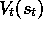 , the estimated value of
, the estimated value of
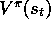 at time t, due to an n
-step backup of
at time t, due to an n
-step backup of 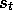 , is defined by
, is defined by
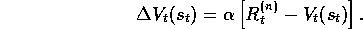
Of course, the increments to the estimated values of the other states
are 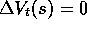 , for all
, for all 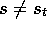 . We define the n
-step backup in terms
of an increment, rather than as a direct update rule as we did in the previous
chapter, in order to distinguish two different ways of making the updates. In
online updating, the updates are done during the episode, as soon as the
increment is computed. In this case we have
. We define the n
-step backup in terms
of an increment, rather than as a direct update rule as we did in the previous
chapter, in order to distinguish two different ways of making the updates. In
online updating, the updates are done during the episode, as soon as the
increment is computed. In this case we have
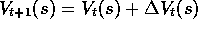 for all
for all 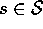 . This is the case considered in
the previous chapter. In offline updating, on the other hand, the
increments are accumulated `on the side' and not used to change
value estimates until the end of the episode. In this case,
. This is the case considered in
the previous chapter. In offline updating, on the other hand, the
increments are accumulated `on the side' and not used to change
value estimates until the end of the episode. In this case, 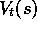 is constant
within an episode, for all s. If its value in this episode is
is constant
within an episode, for all s. If its value in this episode is 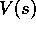 ,
then its new value in the next episode will be
,
then its new value in the next episode will be 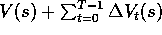 .
.
The expected value of all n
-step returns is guaranteed to improve in a certain
way over the current value function as an approximation to the true value
function. For any V, the expected value of the n
-step return
using V is guaranteed to be a better estimate of 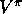 than V is, in a
worst-state sense. That is, the worst error under the new estimate is guaranteed
to be less than or equal to
than V is, in a
worst-state sense. That is, the worst error under the new estimate is guaranteed
to be less than or equal to 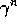 times the worst error under V:
times the worst error under V:
This is called the error-reduction property of n -step returns. Because of the error-correction property, one can show formally that online and offline TD prediction methods using n -step backups converge to the correct predictions under appropriate technical conditions. The n -step TD methods thus form a family of valid methods, with 1-step TD methods and Monte Carlo methods as extreme members.
Nevertheless, n -step TD methods are rarely used because they are inconvenient to implement. Computing n -step returns requires waiting n steps to observe the resultant rewards and states. For large n, this can become problematic, particularly in control applications. The significance of n -step TD methods is primarily for theory and for understanding related methods that are more conveniently implemented. In the next few sections we use the idea of n -steps TD methods to explain and justify eligibility-trace methods.
Example  .
. n
-step TD Methods on the Random Walk.
Consider using n
-step TD methods on the random-walk task described in
Example 6 .2
and shown in Figure 6 .4
. Suppose the
first episode progressed directly from the center state, C, to the right, through
D and E, and then terminated on the right with a return of 1. Recall that the
estimated values of all the states started at an intermediate value,
n
-step TD Methods on the Random Walk.
Consider using n
-step TD methods on the random-walk task described in
Example 6 .2
and shown in Figure 6 .4
. Suppose the
first episode progressed directly from the center state, C, to the right, through
D and E, and then terminated on the right with a return of 1. Recall that the
estimated values of all the states started at an intermediate value, 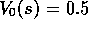 .
As a result of the experience just described, a 1-step method would change only
the estimate for the last state,
.
As a result of the experience just described, a 1-step method would change only
the estimate for the last state, 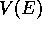 , which would be incremented toward
1, the observed return. A 2-step method, on the other hand, would increment the
values of the two states, D and E, preceding termination:
, which would be incremented toward
1, the observed return. A 2-step method, on the other hand, would increment the
values of the two states, D and E, preceding termination: 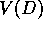 and
and
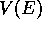 would both be incremented toward 1. A 3-step method, or any n
-step method
for n>2, would increment the values of all three of the visited states towards 1,
all by the same amount. Which n
is better? Figure 7.2
shows the results of a simple empirical assessment for a larger random walk, with
19 states (and with a -1 outcome on the left, all values initialized to 0).
Shown is the root-mean-square error in the predictions at the end of an episode,
averaged over states, the first 10 episodes, and 100 repetitions of the whole
experiment. Results are shown for online and offline n
-step TD methods with a
range of values for n
and
would both be incremented toward 1. A 3-step method, or any n
-step method
for n>2, would increment the values of all three of the visited states towards 1,
all by the same amount. Which n
is better? Figure 7.2
shows the results of a simple empirical assessment for a larger random walk, with
19 states (and with a -1 outcome on the left, all values initialized to 0).
Shown is the root-mean-square error in the predictions at the end of an episode,
averaged over states, the first 10 episodes, and 100 repetitions of the whole
experiment. Results are shown for online and offline n
-step TD methods with a
range of values for n
and  . Empirically, online methods with an intermediate
value of n
seem to work best on this task. This illustrates how the
generalization of TD and Monte Carlo methods to n
-step methods can potentially
perform better than either of the two extreme methods.
. Empirically, online methods with an intermediate
value of n
seem to work best on this task. This illustrates how the
generalization of TD and Monte Carlo methods to n
-step methods can potentially
perform better than either of the two extreme methods.
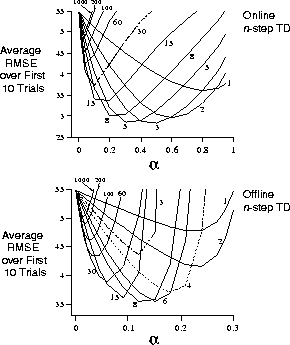
Figure 7.2: Performance of n
-step TD methods as a function of 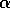 , for various
values of n
, on a 19-state random-walk task. Results are averages over 100
different sets of random walks. The same sets of walks were used with all
methods.
, for various
values of n
, on a 19-state random-walk task. Results are averages over 100
different sets of random walks. The same sets of walks were used with all
methods.
Exercise  .
.
Why do you think a larger random-walk task (19 states instead of 5) was used in the examples of this chapter? Would a smaller walk have shifted the advantage to a different value of How about the change in left-side outcome from 0 to -1? Would that have made any difference in the best value of
Exercise  .
.
Why do you think online methods worked better than offline methods on the example task?
Exercise  .
.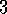 *
*
In the lower part of Figure 7.2, notice that the plot for
n=3 is very different than the others, dropping to low performance at a much
lower value of 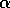 than similar methods. In fact, the same was observed for
n=5, n=7, and n=9. Can you explain why this might have been so? In fact,
we are not sure ourselves.
than similar methods. In fact, the same was observed for
n=5, n=7, and n=9. Can you explain why this might have been so? In fact,
we are not sure ourselves.