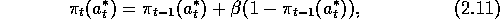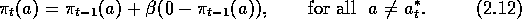Another class of effective learning methods for the n
-armed bandit
problem are pursuit methods. Pursuit methods maintain both
action-value estimates and action preferences, with the preferences
continually ``pursuing" the action that is greedy according to the
current action-value estimates. In the simplest pursuit method, the action
preferences, 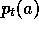 , are the probabilities with which each action, a, is selected
on play t.
, are the probabilities with which each action, a, is selected
on play t.
Just before selecting the action, the probabilities are updated so as to
make the greedy action more likely to be selected. Suppose 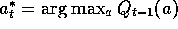 is the greedy action (or a random sample from the
greedy actions if there are more than one) just prior to selecting action
is the greedy action (or a random sample from the
greedy actions if there are more than one) just prior to selecting action
 . Then the probability of selecting
. Then the probability of selecting
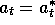 is incremented a fraction,
is incremented a fraction, 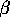 , of the way toward one:
, of the way toward one:
while the probabilities of selecting the other actions are decremented toward zero:
After  is taken and a new reward
observed, the action value,
is taken and a new reward
observed, the action value, 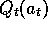 , is updated in one of the ways
discussed in the preceding sections, e.g., to be a sample average
of the observed rewards, using (2.1).
, is updated in one of the ways
discussed in the preceding sections, e.g., to be a sample average
of the observed rewards, using (2.1).
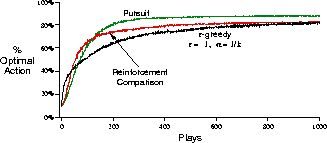
Figure 2.6: Performance of the pursuit method vis-a-vis action-value and
reinforcement-comparison methods on the 10-armed testbed.
Figure 2.6 shows the performance of the pursuit algorithm described
above when the action values were estimated using sample averages (incrementally
computed using 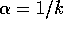 ). In these results, the initial action probabilities
were
). In these results, the initial action probabilities
were
 , for all a and the parameter
, for all a and the parameter 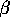 was .01. For comparison, we
also show the performance of an
was .01. For comparison, we
also show the performance of an
 -greedy method (
-greedy method ( ) with action values also estimated using
sample averages. The performance of the reinforcement-comparison algorithm from the
previous section is also shown. Although the pursuit algorithm performs the best of
these three on this task at these parameter settings, the ordering could well be
different in other cases. All three of these methods appear to have their uses
and advantages.
) with action values also estimated using
sample averages. The performance of the reinforcement-comparison algorithm from the
previous section is also shown. Although the pursuit algorithm performs the best of
these three on this task at these parameter settings, the ordering could well be
different in other cases. All three of these methods appear to have their uses
and advantages.
Exercise  .
.
An  -greedy method always selects a random action on a fraction,
-greedy method always selects a random action on a fraction,  , of the
time steps. How about the pursuit algorithm? Will it eventually select the optimal
action with probability approaching certainty?
, of the
time steps. How about the pursuit algorithm? Will it eventually select the optimal
action with probability approaching certainty?
Exercise  .
.
For many of the problems we will encounter later in this book it is not feasible to directly update action probabilities. To use pursuit methods in these cases it is necessary to modify them to use action preferences that are not probabilities, but which determine action probabilities according to a softmax relationship such as the Gibbs distribution (2.8). How can the pursuit algorithm described above be modified to be used in this way? Specify a complete algorithm, including the equations for action-values, preferences, and probabilities at each play.
Exercise  .
.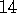 (programming)
(programming)
How well does the algorithm you proposed in
Exercise  .
.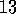
perform? Design and run an experiment assessing the performance of your method. Discuss the role of parameter value settings in your experiment.
Exercise  .
.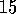
The pursuit algorithm described above is suited only for stationary
environments because the action probabilities converge, albeit slowly, to
certainty. How could you combine the pursuit idea with the  -greedy idea
to obtain a method with performance close to that of the pursuit
algorithm, but which always continues to explore to some small degree?
-greedy idea
to obtain a method with performance close to that of the pursuit
algorithm, but which always continues to explore to some small degree?