Many jobs in industry and elsewhere require completing a collection of tasks while satisfying temporal and resource constraints. Temporal constraints say that some tasks have to be finished before others can be started; resource constraints say that two tasks requiring the same resource cannot be done simultaneously (e.g., the same machine cannot do two tasks at once). The objective is to create a schedule specifying when each task is to begin and what resources it will use that satisfies all the constraints while taking as little overall time as possible. This is the job-shop scheduling problem. In its general form, it is NP-complete, meaning that there is probably no efficient procedure for exactly finding shortest schedules for arbitrary instances of the problem. Job-shop scheduling is usually done using heuristic algorithms that take advantage of special properties of each specific instance.
Zhang and Dietterich (1995, 1996; Zhang, 1996) were motivated to apply reinforcement learning to job-shop scheduling because the design of domain-specific, heuristic algorithms can be expensive and time-consuming. Their goal was to show how reinforcement learning can be used to learn how to quickly find constraint-satisfying schedules of short duration in specific domains, thereby reducing the amount of hand engineering required. They addressed the NASA space shuttle payload processing problem (SSPP), which requires scheduling the tasks required for installation and testing of shuttle cargo bay payloads. An SSPP typically requires scheduling for two to six shuttle missions, each requiring between 34 and 164 tasks. An example of a task is MISSION-SEQUENCE-TEST, which has a duration of 7200 time units and requires the following resources: two quality control officers, two technicians, one ATE, one SPCDS, and one HITS. Some resources are divided into pools, and if a task needs more than one resource of a specific type, the resources must belong to the same pool, and the pool has to be the right one. For example, if a task needs two quality control officers, they both have to be in the pool of quality control officers working on the same shift at the right site. It is not too hard to find a conflict-free schedule for a job, one that meets all the temporal and resource constraints, but the objective is to find a conflict-free schedule with the shortest possible total duration, which is much more difficult.
How can you do this using reinforcement learning? Job-shop scheduling is usually formulated as a search in the space of schedules, what is called a discrete, or combinatorial, optimization problem. A typical solution method would sequentially generate schedules, attempting to improve each over its predecessor in terms of constraint violations and duration (a hill-climbing, or local search, method). You could think of this as a nonassociative reinforcement learning problem of the type we discussed in Chapter 2 with a very large number of possible actions: all the possible schedules! But aside from the problem of having so many actions, any solution obtained this way would just be a single schedule for a single job instance. In contrast, what Zhang and Dietterich wanted their learning system to end up with was a policy that could quickly find good schedules for any SSPP. They wanted it to learn a skill for job-shop scheduling in this specific domain.
For clues about how to do this, they looked to an existing optimization approach to SSPP, in fact, the one actually in use by NASA at the time of their research: the iterative repair method developed by Zweben and Daun (1994). The starting point for the search is a critical path schedule, a schedule that meets the temporal constraints but ignores the resource constraints. This schedule can be constructed efficiently by scheduling each task prior to launch as late as the temporal constraints permit, and each task after landing as early as these constraints permit. Resource pools are assigned randomly. Two types of operators are used to modify schedules. They can be applied to any task that violates a resource constraint. A REASSIGN-POOL operator changes the pool assigned to one of the task's resources. This type of operator applies only if it can reassign a pool so that the resource requirement is satisfied. A MOVE operator moves a task to the first earlier or later time at which its resource needs can be satisfied and uses the critical path method to reschedule all of the task's temporal dependents.
At each step of the iterative
repair search, one operator is applied to the current schedule, selected according
to the following rules. The earliest task with a resource constraint violation is
found, and a REASSIGN-POOL operator is applied to this task if
possible. If more than one applies, that is, if several different pool
reassignments are possible, one is selected at random. If no REASSIGN-POOL operator applies, then a
MOVE operator is selected at random based on a heuristic that prefers
short-distance moves of tasks having few temporal dependents and whose resource
requirements are close to the task's overallocation. After an operator is
applied, the number of constraint violations of the resulting schedule is
determined. A simulated annealing procedure is used decide whether to accept or
reject this new schedule. If ![]() denotes the number of constraint
violations removed by the repair, then the new schedule is accepted with
probability
denotes the number of constraint
violations removed by the repair, then the new schedule is accepted with
probability ![]() , where
, where ![]() is the current computational
temperature that is gradually decreased throughout the search. If accepted, the
new schedule becomes the current schedule for the next iteration; otherwise, the
algorithm attempts to repair the old schedule again, which will usually produce
different results due to the random decisions involved. Search stops when all
constraints are satisfied. Short schedules are obtained by running the algorithm
several times and selecting the shortest of the resulting conflict-free
schedules.
is the current computational
temperature that is gradually decreased throughout the search. If accepted, the
new schedule becomes the current schedule for the next iteration; otherwise, the
algorithm attempts to repair the old schedule again, which will usually produce
different results due to the random decisions involved. Search stops when all
constraints are satisfied. Short schedules are obtained by running the algorithm
several times and selecting the shortest of the resulting conflict-free
schedules.
Zhang and Dietterich treated entire schedules as states in the sense of
reinforcement learning. The actions were the applicable REASSIGN-POOL and
MOVE operators, typically numbering about 20. The problem was treated as
episodic, each episode starting with the same critical path schedule that the
iterative repair algorithm would start with and ending when a schedule was found
that did not violate any constraint. The initial state--a critical path
schedule--is denoted ![]() . The rewards were designed to promote the quick
construction of conflict-free schedules of short duration. The system received a
small negative reward (
. The rewards were designed to promote the quick
construction of conflict-free schedules of short duration. The system received a
small negative reward (![]() ) on each step that resulted in a schedule that
still violated a constraint. This encouraged the agent to find conflict-free
schedules quickly, that is, with a small number of repairs to
) on each step that resulted in a schedule that
still violated a constraint. This encouraged the agent to find conflict-free
schedules quickly, that is, with a small number of repairs to ![]() . Encouraging
the system to find short schedules is more difficult because what it means for a
schedule to be short depends on the specific SSPP instance. The shortest
schedule for a difficult instance, one with a lot of tasks and constraints, will
be longer than the shortest schedule for a simpler instance. Zhang and
Dietterich devised a formula for a resource dilation factor (RDF),
intended to be an instance-independent measure of a schedule's duration. To
account for an instance's intrinsic difficulty, the formula makes use of a
measure of the resource overallocation of
. Encouraging
the system to find short schedules is more difficult because what it means for a
schedule to be short depends on the specific SSPP instance. The shortest
schedule for a difficult instance, one with a lot of tasks and constraints, will
be longer than the shortest schedule for a simpler instance. Zhang and
Dietterich devised a formula for a resource dilation factor (RDF),
intended to be an instance-independent measure of a schedule's duration. To
account for an instance's intrinsic difficulty, the formula makes use of a
measure of the resource overallocation of ![]() . Since longer schedules tend to
produce larger RDFs, the negative of the RDF of the final conflict-free schedule
was used as a reward at the end of each episode. With this reward function, if
it takes
. Since longer schedules tend to
produce larger RDFs, the negative of the RDF of the final conflict-free schedule
was used as a reward at the end of each episode. With this reward function, if
it takes ![]() repairs starting from a schedule
repairs starting from a schedule ![]() to obtain a final
conflict-free schedule,
to obtain a final
conflict-free schedule,
![]() , the return from
, the return from ![]() is
is ![]() .
.
This reward function was designed to try to make a system learn to satisfy the two
goals of finding conflict-free schedules of short duration and finding
conflict-free schedules quickly. But the reinforcement learning system really has
only one goal--maximizing expected return--so the particular reward values
determine how a learning system will tend to trade off these two goals. Setting
the immediate reward to the small value of ![]() means that the learning system
will regard one repair, one step in the scheduling process, as being worth
means that the learning system
will regard one repair, one step in the scheduling process, as being worth ![]() units of RDF. So, for example, if from some schedule it is possible to produce a
conflict-free schedule with one repair or with two, an optimal policy will take
extra repair only if it promises a reduction in final RDF of more than
units of RDF. So, for example, if from some schedule it is possible to produce a
conflict-free schedule with one repair or with two, an optimal policy will take
extra repair only if it promises a reduction in final RDF of more than ![]() .
.
Zhang and Dietterich used TD(![]() ) to learn the value
function. Function approximation was by a multilayer neural network trained by
backpropagating TD errors. Actions were selected by an
) to learn the value
function. Function approximation was by a multilayer neural network trained by
backpropagating TD errors. Actions were selected by an
![]() -greedy policy, with
-greedy policy, with ![]() decreasing during learning. One-step lookahead search
was used to find the greedy action. Their knowledge of the problem made it easy to
predict the schedules that would result from each repair operation. They
experimented with a number of modifications to this basic procedure to
improve its performance. One was to use the TD(
decreasing during learning. One-step lookahead search
was used to find the greedy action. Their knowledge of the problem made it easy to
predict the schedules that would result from each repair operation. They
experimented with a number of modifications to this basic procedure to
improve its performance. One was to use the TD(![]() ) algorithm backward after each episode, with the eligibility trace extending to future
rather than to past states. Their results suggested that this was
more accurate and efficient than forward learning. In updating the weights of the
network, they also sometimes performed multiple weight updates when the TD error
was large. This is apparently equivalent to dynamically varying the step-size
parameter in an error-dependent way during learning.
) algorithm backward after each episode, with the eligibility trace extending to future
rather than to past states. Their results suggested that this was
more accurate and efficient than forward learning. In updating the weights of the
network, they also sometimes performed multiple weight updates when the TD error
was large. This is apparently equivalent to dynamically varying the step-size
parameter in an error-dependent way during learning.
They also tried an experience replay technique due to Lin (1992). At any point in learning, the agent remembered the best episode up to that point. After every four episodes, it replayed this remembered episode, learning from it as if it were a new episode. At the start of training, they similarly allowed the system to learn from episodes generated by a good scheduler, and these could also be replayed later in learning. To make the lookahead search faster for large-scale problems, which typically had a branching factor of about 20, they used a variant they called random sample greedy search that estimated the greedy action by considering only random samples of actions, increasing the sample size until a preset confidence was reached that the greedy action of the sample was the true greedy action. Finally, having discovered that learning could be slowed considerably by excessive looping in the scheduling process, they made their system explicitly check for loops and alter action selections when a loop was detected. Although all of these techniques could improve the efficiency of learning, it is not clear how crucial all of them were for the success of the system.
Zhang and Dietterich experimented with two different network architectures. In the first version of their system, each schedule was represented using a set of 20 handcrafted features. To define these features, they studied small scheduling problems to find features that had some ability to predict RDF. For example, experience with small problems showed that only four of the resource pools tended to cause allocation problems. The mean and standard deviation of each of these pools' unused portions over the entire schedule were computed, resulting in 10 real-valued features. Two other features were the RDF of the current schedule and the percentage of its duration during which it violated resource constraints. The network had 20 input units, one for each feature, a hidden layer of 40 sigmoidal units, and an output layer of 8 sigmoidal units. The output units coded the value of a schedule using a code in which, roughly, the location of the activity peak over the 8 units represented the value. Using the appropriate TD error, the network weights were updated using error backpropagation, with the multiple weight-update technique mentioned above.
The second version of the system (Zhang and Dietterich, 1996) used a more complicated time-delay neural network (TDNN) borrowed from the field of speech recognition (Lang, Waibel, and Hinton, 1990). This version divided each schedule into a sequence of blocks (maximal time intervals during which tasks and resource assignments did not change) and represented each block by a set of features similar to those used in the first program. It then scanned a set of "kernel" networks across the blocks to create a set of more abstract features. Since different schedules had different numbers of blocks, another layer averaged these abstract features over each third of the blocks. Then a final layer of 8 sigmoidal output units represented the schedule's value using the same code as in the first version of the system. In all, this network had 1123 adjustable weights.
A set of 100 artificial scheduling problems was constructed and
divided into subsets used for training, determining when to stop training (a
validation set), and final testing. During training they tested
the system on the validation set after every 100 episodes and stopped training when
performance on the validation set stopped changing, which generally took about
10,000 episodes. They trained networks with different values of ![]() (0.2 and 0.7), with three different training sets, and they saved both the final
set of weights and the set of weights producing the best performance on the
validation set. Counting each set of weights as a different network, this
produced 12 networks, each of which corresponded to a different scheduling
algorithm.
(0.2 and 0.7), with three different training sets, and they saved both the final
set of weights and the set of weights producing the best performance on the
validation set. Counting each set of weights as a different network, this
produced 12 networks, each of which corresponded to a different scheduling
algorithm.
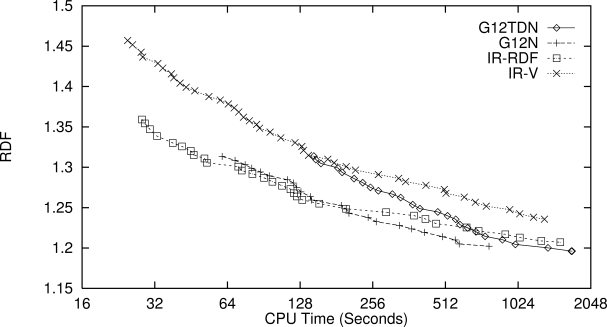
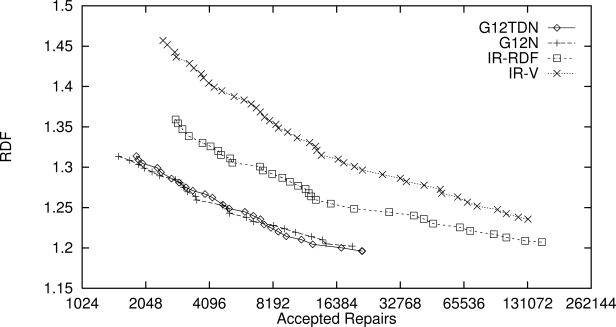
Figure 11.11 shows how the mean performance of the 12 TDNN networks (labeled G12TDN) compared with the performances of two versions of Zweben and Daun's iterative repair algorithm, one using the number of constraint violations as the function to be minimized by simulated annealing (IR-V) and the other using the RDF measure (IR-RDF). The figure also shows the performance of the first version of their system that did not use a TDNN (G12N). The mean RDF of the best schedule found by repeatedly running an algorithm is plotted against the total number of schedule repairs (using a log scale). These results show that the learning system produced scheduling algorithms that needed many fewer repairs to find conflict-free schedules of the same quality as those found by the iterative repair algorithms. Figure 11.12 compares the computer time required by each scheduling algorithm to find schedules of various RDFs. According to this measure of performance, the best trade-off between computer time and schedule quality is produced by the non-TDNN algorithm (G12N). The TDNN algorithm (G12TDN) suffered due to the time it took to apply the kernel-scanning process, but Zhang and Dietterich point out that there are many ways to make it run faster.
|
These results do not unequivocally establish the utility of reinforcement learning for job-shop scheduling or for other difficult search problems. But they do suggest that it is possible to use reinforcement learning methods to learn how to improve the efficiency of search. Zhang and Dietterich's job-shop scheduling system is the first successful instance of which we are aware in which reinforcement learning was applied in plan-space, that is, in which states are complete plans (job-shop schedules in this case), and actions are plan modifications. This is a more abstract application of reinforcement learning than we are used to thinking about. Note that in this application the system learned not just to efficiently create one good schedule, a skill that would not be particularly useful; it learned how to quickly find good schedules for a class of related scheduling problems. It is clear that Zhang and Dietterich went through a lot of trial-and-error learning of their own in developing this example. But remember that this was a groundbreaking exploration of a new aspect of reinforcement learning. We expect that future applications of this kind and complexity will become more routine as experience accumulates.