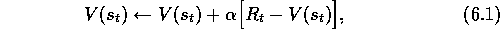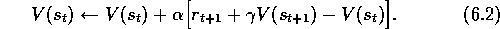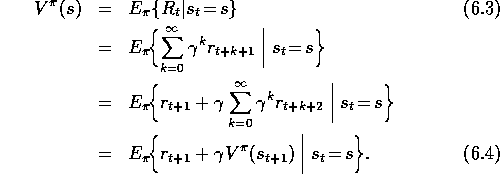Both TD and Monte Carlo methods use experience to solve the prediction problem.
Given some experience following a policy  , both methods update their estimate
V of
, both methods update their estimate
V of 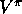 . If a nonterminal state
. If a nonterminal state 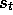 is visited at time t, then both
methods update their estimate
is visited at time t, then both
methods update their estimate 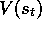 based on what happens after that visit.
Roughly speaking, Monte Carlo methods wait until the return following the
visit is known, then use that return as a target for
based on what happens after that visit.
Roughly speaking, Monte Carlo methods wait until the return following the
visit is known, then use that return as a target for 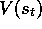 . A simple
every-visit Monte Carlo method suitable for nonstationary environments is
. A simple
every-visit Monte Carlo method suitable for nonstationary environments is
where 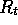 is the actual return following time t and
is the actual return following time t and
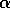 is a constant step-size parameter. Let us call this method
constant-
is a constant step-size parameter. Let us call this method
constant-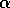 MC. Whereas Monte Carlo methods must wait until
the end of the episode to determine the increment to
MC. Whereas Monte Carlo methods must wait until
the end of the episode to determine the increment to  (only then is
(only then is 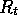 known), TD methods need wait only until the next time step. At time
t+1 they immediately form a target and make a useful update using
the observed reward
known), TD methods need wait only until the next time step. At time
t+1 they immediately form a target and make a useful update using
the observed reward
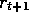 and the estimate
and the estimate
 . The simplest TD method, known as TD(0), is
. The simplest TD method, known as TD(0), is
In effect, the target for the Monte Carlo update is 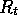 ,
whereas the target for the TD update is
,
whereas the target for the TD update is  .
.
Because the TD method bases its update in part on an existing estimate, we say that it is a bootstrapping method, like DP. We know from Chapter 3 that
Roughly speaking, Monte Carlo methods use an estimate of (6.3) as a
target, whereas DP methods use an estimate of (6.4) as a target. The
Monte Carlo target is an estimate because the expected value in (6.3) is
not known; a sample return is used in place of the real expected return. The DP
target is an estimate not because of the expected values, which are assumed to be
completely provided by a model of the environment, but because
 is not known and the current
estimate,
is not known and the current
estimate,  , is used instead. The TD target is an estimate
for both reasons: it samples the expected values in (6.4)
and it uses the current estimate
, is used instead. The TD target is an estimate
for both reasons: it samples the expected values in (6.4)
and it uses the current estimate 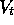 instead of the true
instead of the true 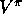 . Thus, TD
methods combine the sampling of Monte Carlo with the bootstrapping of DP. As
we shall see, with care and imagination this can take us a long way
toward obtaining the advantages of both Monte Carlo and DP methods.
. Thus, TD
methods combine the sampling of Monte Carlo with the bootstrapping of DP. As
we shall see, with care and imagination this can take us a long way
toward obtaining the advantages of both Monte Carlo and DP methods.
Figure 6.2 specifies TD(0) completely in procedural form, and Figure 6.1 shows its backup diagram. The value estimate for the state node at the top of the backup diagram is updated based on the one sample transition from it to the immediately following state. We refer to TD and Monte Carlo updates as sample backups because they involve looking ahead to a sample successor state (or state-action pair), using the value of the successor and the reward along the way to compute a backed-up value, and then changing the value of the original state (or state-action pair) accordingly. Sample backups differ from the full backups of DP methods in that they are based on a single sample successor rather than on a complete distribution of all possible successors.
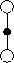
Figure 6.1: The backup diagram for the TD(0) algorithm.
Initializearbitrarily,
to the policy to be evaluated Repeat (for each episode): Initialize s Repeat (for each step of episode):
Take action a; observe reward, r, and next state,
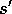
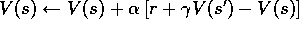
until s is terminal
 .
.
Example  .
.
Driving Home. Each day you drive home from work and you try to predict how long it will take to get home. When you leave your office, you note the time, the day of week, and anything else that might be relevant. Say on this friday you are leaving at exactly 6 o'clock, and you estimate that it will take 30 minutes to get home. As you reach your car it is 6:05 and you notice it is starting to rain. Traffic is often slower in the rain so you re-estimate that it will take 35 minutes from then, or a total of 40 minutes. Fifteen minutes later you have completed the highway portion of your journey in good time. As you exit onto a secondary road you cut your estimate of total travel time to 35 minutes. Unfortunately, at this point you get stuck behind a slow truck, and the road is too narrow to pass. You end up having to follow the truck until you turn off onto the side street where you live at 6:40. Three minutes later you are home. The sequence of situations, times, and predictions is thus as follows:
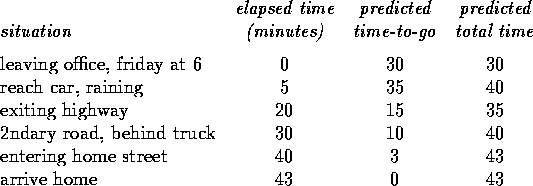
The rewards in this example are the elapsed times on each leg of the
journey. We are not
discounting (
We are not
discounting (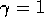 ) and thus the return for each situation is the actual
time-to-go from that situation. The value of each situation is the expected
time-to-go. The second column of numbers gives the current estimated value for each
situation encountered.
) and thus the return for each situation is the actual
time-to-go from that situation. The value of each situation is the expected
time-to-go. The second column of numbers gives the current estimated value for each
situation encountered.
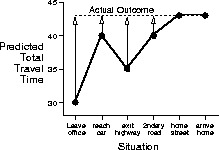
Figure 6.3: Changes recommended by Monte Carlo methods in the
driving-home example.
A simple way to view the operation of Monte Carlo methods is to
plot the predicted total time (the last column) over the sequence, as in
Figure 6.3. The arrows show the changes in
predictions recommended by the constant- MC method (6.1). These are
exactly the errors between the estimated value (predicted time-to-go) in each
situation and the actual return (actual time-to-go). For example, when you exited the
highway you thought it would take only 15 minutes more to get home, but in fact it
took 23 minutes. Equation 6.1 applies at this point and determines an
increment in the estimate of time-to-go after exiting the highway. The error,
MC method (6.1). These are
exactly the errors between the estimated value (predicted time-to-go) in each
situation and the actual return (actual time-to-go). For example, when you exited the
highway you thought it would take only 15 minutes more to get home, but in fact it
took 23 minutes. Equation 6.1 applies at this point and determines an
increment in the estimate of time-to-go after exiting the highway. The error,
 , at this time is 8 minutes. Suppose the step
size
, at this time is 8 minutes. Suppose the step
size 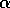 is
is  . Then the predicted time-to-go after exiting the
highway would be revised upward by 4 minutes as a result of this
experience. This is probably too large of a change in this case; the truck was
probably just an unlucky break. In any event, the change can only be made
offline, that is, after you have reached home. Only at this point do you know
any of the actual returns.
. Then the predicted time-to-go after exiting the
highway would be revised upward by 4 minutes as a result of this
experience. This is probably too large of a change in this case; the truck was
probably just an unlucky break. In any event, the change can only be made
offline, that is, after you have reached home. Only at this point do you know
any of the actual returns.
Is it necessary to wait until the final outcome is known before learning can begin? Suppose on another day you again estimate when leaving your office that it will take 30 minutes to drive home, but then you become stuck in a massive traffic jam. Twenty-five minutes after leaving the office you are still bumper-to-bumper on the highway. You now estimate that it will take another 25 minutes to get home, for a total of 50 minutes. As you wait in traffic you already know that your initial estimate of 30 minutes was too optimistic. Must you wait until you get home before increasing your estimate for the initial situation? According to the Monte Carlo approach you must, because you don't yet know the true return.
According to a TD approach, on the other hand, you would learn immediately,
shifting your initial estimate from 30 minutes toward 50. In fact, each estimate
would be shifted toward the estimate that immediately follows it. Returning to
our first day of driving, Figure 6.4 shows the same predictions as
Figure 6.3 except here showing the changes recommended
by the TD rule (6.2) (these are the changes made by the rule if
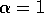 ). Each error is proportional to the change over time of the prediction,
i.e., learning is driven by the temporal differences in prediction.
). Each error is proportional to the change over time of the prediction,
i.e., learning is driven by the temporal differences in prediction.
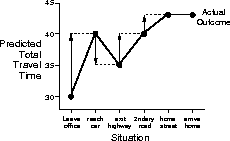
Figure 6.4: Changes recommended by TD methods in the
driving-home example.
Besides giving you something to do while waiting in traffic, there are several computational reasons why it is advantageous to learn based in part on your current predictions rather than waiting until termination when you know the actual return. We briefly discuss some of these next.