


We are now ready to present an example of the second class of learning control methods we consider in this book: off-policy methods. Recall that the distinguishing feature of on-policy methods is that they estimate the value of a policy while using it for control. In off-policy methods these two functions are separated. The policy used to generate behavior, called the behavior policy, may in fact be unrelated to the policy that is evaluated and improved, called the estimation policy. An advantage of this separation is that the estimation policy may be deterministic, e.g., greedy, while the behavior policy can continue to sample all possible actions.
Off-policy Monte Carlo control methods use the technique presented in the preceding section for estimating the value function for one policy while following another. They follow the behavior policy while learning about and improving the estimation policy. This technique requires that the behavior policy have a nonzero probability of selecting all actions that might be selected by the estimation policy. To explore all possibilities, we require that the behavior policy be soft.
Initialize, for all,
:
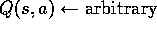
; Numerator and
; Denominator of
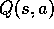
Repeat Forever: (a) Select a policy
and use it to generate an episode:
(b)
(c) For each pair s,a appearing in the episode after
:
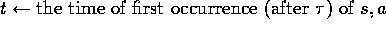
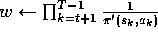
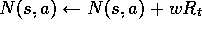
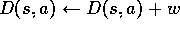
(d) For each
:
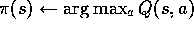
Figure 5.7 shows an off-policy Monte Carlo method, based on
GPI, for computing 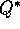 .
The behavior policy
.
The behavior policy 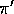 is maintained as an
arbitrary soft policy. The estimation policy
is maintained as an
arbitrary soft policy. The estimation policy  is the greedy policy
with respect to Q, an estimate of
is the greedy policy
with respect to Q, an estimate of
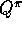 . The
behavior policy chosen in (a) can be anything, but in order to assure
convergence of
. The
behavior policy chosen in (a) can be anything, but in order to assure
convergence of  to the optimal policy, an infinite number of returns
suitable for use in (c) must be obtained for each pair of state and
action. This can be assured by careful choice of the behavior policy. For
example, any
to the optimal policy, an infinite number of returns
suitable for use in (c) must be obtained for each pair of state and
action. This can be assured by careful choice of the behavior policy. For
example, any  -soft behavior policy will suffice.
-soft behavior policy will suffice.
A potential problem is that this method only learns from the tails of episodes, after the last non-greedy action. If non-greedy actions are frequent, then learning will be very slow, particularly for states appearing in the early portions of long episodes. Potentially, this could greatly slow learning. There has been insufficient experience with off-policy Monte Carlo methods to assess how serious this problem is.
Exercise  .
. (programming)
Racetrack.
Consider driving a race car around a turn like those shown in
Figure 5.8. You want to go as fast as possible, but not so
fast as to run off the track. In our simplified racetrack, the car is at one
of a discrete set of grid positions, the cells in the diagram. The velocity is
also discrete, a number of grid cells moved horizontally and vertically per
time step. The actions are increments to the velocity components. Each may
be changed by +1, -1, or 0 in one step, for a total of nine actions.
Both components are restricted to be non-negative and less than 5, and they
cannot both be zero. Each trial begins in one of the randomly selected start
states and ends when the car crosses the finish line. The rewards are -1
for each step that stays on the track, and -5 if the agent tries to drive
off the track. Actually leaving the track is not allowed, but the state is
always advanced at least one cell along the horizontal or vertical axes.
With these restrictions and considering only right turns, such as shown in
the figure, all episodes are guaranteed to terminate, yet the optimal policy is
unlikely to be excluded. To make the task more challenging, we assume that
on half of the time steps the position is displaced forward or to the right by
one additional cell beyond that specified by the velocity. Apply the on-policy
Monte Carlo control method to this task to compute the optimal policy from
each starting state. Exhibit several trajectories following the optimal
policy.
(programming)
Racetrack.
Consider driving a race car around a turn like those shown in
Figure 5.8. You want to go as fast as possible, but not so
fast as to run off the track. In our simplified racetrack, the car is at one
of a discrete set of grid positions, the cells in the diagram. The velocity is
also discrete, a number of grid cells moved horizontally and vertically per
time step. The actions are increments to the velocity components. Each may
be changed by +1, -1, or 0 in one step, for a total of nine actions.
Both components are restricted to be non-negative and less than 5, and they
cannot both be zero. Each trial begins in one of the randomly selected start
states and ends when the car crosses the finish line. The rewards are -1
for each step that stays on the track, and -5 if the agent tries to drive
off the track. Actually leaving the track is not allowed, but the state is
always advanced at least one cell along the horizontal or vertical axes.
With these restrictions and considering only right turns, such as shown in
the figure, all episodes are guaranteed to terminate, yet the optimal policy is
unlikely to be excluded. To make the task more challenging, we assume that
on half of the time steps the position is displaced forward or to the right by
one additional cell beyond that specified by the velocity. Apply the on-policy
Monte Carlo control method to this task to compute the optimal policy from
each starting state. Exhibit several trajectories following the optimal
policy.
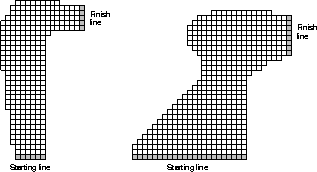
Figure 5.8: A couple of right turns for the racetrack task.