


In this chapter we consider our first learning methods for estimating value functions and discovering optimal policies. Unlike the previous chapter, here we do not assume complete knowledge of the environment. Monte Carlo methods require only experience---sample sequences of states, actions, and rewards from actual or simulated interaction with an environment. Learning from actual experience is striking because it requires no prior knowledge of the environment's dynamics, yet can still attain optimal behavior. Learning from simulated experience is also very powerful. Although a model is still required, the model need only generate sample transitions, not the complete probability distributions of all possible transitions that is required by DP methods. In surprisingly many cases it is easy to generate experience sampled according to the desired probability distributions, but infeasible to obtain the distributions in explicit form.
Monte Carlo methods are ways of solving the reinforcement learning problem based on averaging sample returns. To ensure that well-defined returns are available, we define Monte Carlo methods only for episodic tasks. That is, we assume experience is divided into episodes, and that all episodes eventually terminate no matter what actions are selected. It is only upon the completion of an episode that value estimates and policies are changed. Monte Carlo methods are thus incremental in an episode-by-episode sense, but not in a step-by-step sense. The term ``Monte Carlo" is sometimes used more broadly for any estimation method whose operation involves a significant random component. Here we use it specifically for methods based on averaging complete returns (as opposed to methods that learn from partial returns, considered in the next chapter).
Despite the differences between Monte Carlo and dynamic programming (DP)
methods, the most important ideas carry over from DP to the Monte Carlo case.
Not only do we compute the same value functions, but they
interact to attain optimality in essentially the same way. Just as in the DP
chapter, we consider first policy evaluation, the computation of 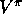 and
and
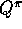 for a fixed arbitrary policy
for a fixed arbitrary policy  , then policy
improvement, and, finally, generalized policy iteration. Each of these ideas
taken from DP is extended to the Monte Carlo case in
which only sample experience is available.
, then policy
improvement, and, finally, generalized policy iteration. Each of these ideas
taken from DP is extended to the Monte Carlo case in
which only sample experience is available.