TD methods learn their estimates in part on the basis of other estimates. They learn a guess from a guess--they bootstrap. Is this a good thing to do? What advantages do TD methods have over Monte Carlo and DP methods? Developing and answering such questions will take the rest of this book and more. In this section we briefly anticipate some of the answers.
Obviously, TD methods have an advantage over DP methods in that they do not require a model of the environment, of its reward and next-state probability distributions.
The next most obvious advantage of TD methods over Monte Carlo methods is that they are naturally implemented in an on-line, fully incremental fashion. With Monte Carlo methods one must wait until the end of an episode, because only then is the return known, whereas with TD methods one need wait only one time step. Surprisingly often this turns out to be a critical consideration. Some applications have very long episodes, so that delaying all learning until an episode's end is too slow. Other applications are continuing tasks and have no episodes at all. Finally, as we noted in the previous chapter, some Monte Carlo methods must ignore or discount episodes on which experimental actions are taken, which can greatly slow learning. TD methods are much less susceptible to these problems because they learn from each transition regardless of what subsequent actions are taken.
But are TD methods sound? Certainly it is convenient to learn one guess from the
next, without waiting for an actual outcome, but can we still guarantee
convergence to the correct answer? Happily, the answer is yes. For any fixed
policy ![]() , the TD algorithm described above has been proved to converge to
, the TD algorithm described above has been proved to converge to
![]() , in the mean for a constant step-size parameter if it is sufficiently small,
and with probability 1 if the step-size parameter decreases according to the
usual stochastic approximation conditions (2.8). Most
convergence proofs apply only to the table-based case of the algorithm presented
above (6.2), but some also apply to the case of general linear function
approximation. These results are discussed in a more general setting in the
next two chapters.
, in the mean for a constant step-size parameter if it is sufficiently small,
and with probability 1 if the step-size parameter decreases according to the
usual stochastic approximation conditions (2.8). Most
convergence proofs apply only to the table-based case of the algorithm presented
above (6.2), but some also apply to the case of general linear function
approximation. These results are discussed in a more general setting in the
next two chapters.
If both TD and Monte Carlo methods converge asymptotically to the correct predictions, then
a natural next question is "Which gets there first?" In other words, which
method learns faster? Which makes the more efficient use of limited data? At
the current time this is an open question in the sense that no one has been able
to prove mathematically that one method converges faster than the other. In
fact, it is not even clear what is the most appropriate formal way to phrase
this question! In practice, however, TD methods have usually been found to
converge faster than constant-![]() MC methods on stochastic tasks, as illustrated
in the following example.
MC methods on stochastic tasks, as illustrated
in the following example.
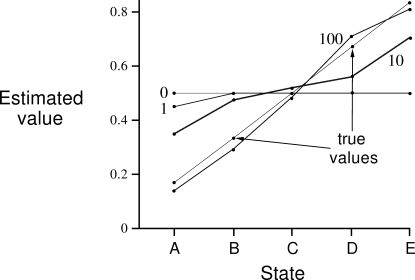
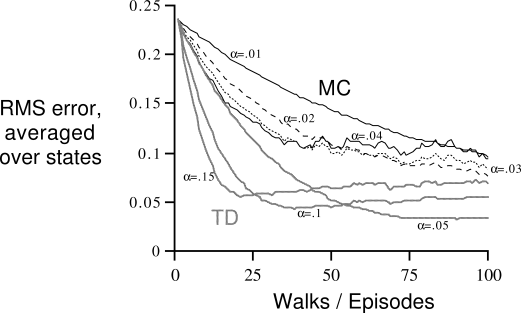
Example 6.2: Random Walk In this example we empirically compare the prediction abilities of TD(0) and constant-

Exercise 6.1 This is an exercise to help develop your intuition about why TD methods are often more efficient than Monte Carlo methods. Consider the driving home example and how it is addressed by TD and Monte Carlo methods. Can you imagine a scenario in which a TD update would be better on average than an Monte Carlo update? Give an example scenario--a description of past experience and a current state--in which you would expect the TD update to be better. Here's a hint: Suppose you have lots of experience driving home from work. Then you move to a new building and a new parking lot (but you still enter the highway at the same place). Now you are starting to learn predictions for the new building. Can you see why TD updates are likely to be much better, at least initially, in this case? Might the same sort of thing happen in the original task?
Exercise 6.2 From Figure 6.6, it appears that the first episode results in a change in only
Exercise 6.3 Do you think that by choosing the step-size parameter,
Exercise 6.4 In Figure 6.7, the RMS error of the TD method seems to go down and then up again, particularly at high
Exercise 6.5 Above we stated that the true values for the random walk task are