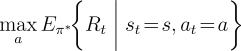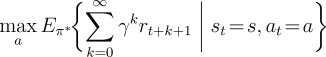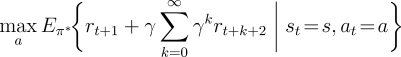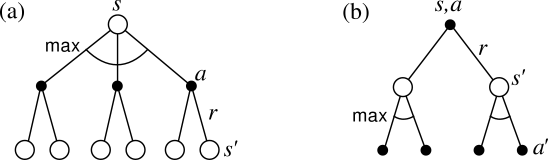Solving a reinforcement learning task means, roughly, finding a policy that
achieves a lot of reward over the long run. For finite
MDPs, we can precisely define an optimal policy in the following way.
Value functions define a partial ordering over policies. A policy ![]() is defined to be better than or equal to a policy
is defined to be better than or equal to a policy ![]() if its expected return
is greater than or equal to that of
if its expected return
is greater than or equal to that of ![]() for all states. In other words,
for all states. In other words,
![]() if and only if
if and only if
![]() for all
for all ![]() . There is always at least one
policy that is better than or equal to all other policies. This is an optimal policy. Although there may be more than one, we denote all the optimal
policies by
. There is always at least one
policy that is better than or equal to all other policies. This is an optimal policy. Although there may be more than one, we denote all the optimal
policies by ![]() . They share the same state-value function, called the optimal state-value function, denoted
. They share the same state-value function, called the optimal state-value function, denoted
![]() , and defined as
, and defined as
Optimal policies also share the same optimal action-value function,
denoted
![]() , and defined as
, and defined as
Example 3.10: Optimal Value Functions for Golf The lower part of Figure 3.6 shows the contours of a possible optimal action-value function

Because ![]() is the value function for a policy, it must satisfy the
self-consistency condition given by the Bellman equation for
state values (3.10). Because it is the optimal value function,
however,
is the value function for a policy, it must satisfy the
self-consistency condition given by the Bellman equation for
state values (3.10). Because it is the optimal value function,
however, ![]() 's consistency condition can be written in a special form without
reference to any specific policy. This is the Bellman equation for
's consistency condition can be written in a special form without
reference to any specific policy. This is the Bellman equation for ![]() , or the
Bellman optimality equation. Intuitively,
the Bellman optimality equation expresses the fact that the value of a state under
an optimal policy must equal the expected return for the best action from that state:
, or the
Bellman optimality equation. Intuitively,
the Bellman optimality equation expresses the fact that the value of a state under
an optimal policy must equal the expected return for the best action from that state:
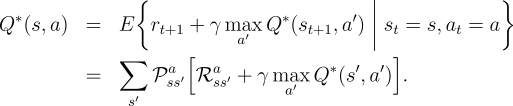
|
The backup diagrams in Figure
3.7 show graphically the spans of
future states and actions considered in the Bellman optimality equations for ![]() and
and
![]() . These are the same as the backup diagrams for
. These are the same as the backup diagrams for ![]() and
and ![]() except
that arcs have been added at the agent's choice points to represent that the maximum
over that choice is taken rather than the expected value given some policy.
Figure
3.7a graphically represents the Bellman optimality
equation (3.15).
except
that arcs have been added at the agent's choice points to represent that the maximum
over that choice is taken rather than the expected value given some policy.
Figure
3.7a graphically represents the Bellman optimality
equation (3.15).
For finite MDPs, the Bellman optimality equation (3.15) has a unique
solution independent of the policy. The
Bellman optimality equation is actually a system of equations, one for each state,
so if there are ![]() states, then there are
states, then there are ![]() equations in
equations in ![]() unknowns.
If the dynamics of the environment are known (
unknowns.
If the dynamics of the environment are known (![]() and
and ![]() ), then
in principle one can solve this system of equations for
), then
in principle one can solve this system of equations for ![]() using any one of a
variety of methods for solving systems of nonlinear equations. One can solve a
related set of equations for
using any one of a
variety of methods for solving systems of nonlinear equations. One can solve a
related set of equations for
![]() .
.
Once one has ![]() , it is relatively easy to determine an optimal policy.
For each state
, it is relatively easy to determine an optimal policy.
For each state ![]() , there will be one or more actions at which the maximum is obtained
in the Bellman optimality equation.
Any policy that assigns nonzero probability only to these actions is an optimal
policy. You can think of this as a one-step search. If you have the optimal value
function,
, there will be one or more actions at which the maximum is obtained
in the Bellman optimality equation.
Any policy that assigns nonzero probability only to these actions is an optimal
policy. You can think of this as a one-step search. If you have the optimal value
function, ![]() , then the actions that appear best after a one-step search
will be optimal actions.
Another way of saying this is that any policy that is greedy with respect to the optimal evaluation function
, then the actions that appear best after a one-step search
will be optimal actions.
Another way of saying this is that any policy that is greedy with respect to the optimal evaluation function ![]() is an optimal
policy. The term greedy is used in computer science to describe any search or decision
procedure that selects alternatives based only on local or immediate considerations,
without considering the possibility that such a selection may prevent future access
to even better alternatives. Consequently, it describes policies
that select actions based only on their short-term consequences. The beauty of
is an optimal
policy. The term greedy is used in computer science to describe any search or decision
procedure that selects alternatives based only on local or immediate considerations,
without considering the possibility that such a selection may prevent future access
to even better alternatives. Consequently, it describes policies
that select actions based only on their short-term consequences. The beauty of
![]() is that if one uses it to evaluate the short-term
consequences of actions--specifically, the one-step consequences--then
a greedy policy is actually optimal in the long-term sense in which we are
interested because
is that if one uses it to evaluate the short-term
consequences of actions--specifically, the one-step consequences--then
a greedy policy is actually optimal in the long-term sense in which we are
interested because ![]() already takes into account the reward consequences of all
possible future behavior. By means of
already takes into account the reward consequences of all
possible future behavior. By means of ![]() , the optimal expected long-term return is
turned into a quantity that is locally and immediately available for each state.
Hence, a one-step-ahead search yields the long-term optimal actions.
, the optimal expected long-term return is
turned into a quantity that is locally and immediately available for each state.
Hence, a one-step-ahead search yields the long-term optimal actions.
Having ![]() makes choosing optimal actions still
easier. With
makes choosing optimal actions still
easier. With ![]() , the agent does not even have to do a one-step-ahead search: for
any state
, the agent does not even have to do a one-step-ahead search: for
any state ![]() , it can simply find any action that maximizes
, it can simply find any action that maximizes ![]() . The
action-value function effectively caches the results of all one-step-ahead
searches. It provides the optimal expected long-term return as a value that is
locally and immediately available for each state-action pair. Hence, at the
cost of representing a function of state-action pairs, instead of just
of states, the optimal action-value function allows optimal actions to be
selected without having to know anything about possible successor states and
their values, that is, without having to know anything about the environment's
dynamics.
. The
action-value function effectively caches the results of all one-step-ahead
searches. It provides the optimal expected long-term return as a value that is
locally and immediately available for each state-action pair. Hence, at the
cost of representing a function of state-action pairs, instead of just
of states, the optimal action-value function allows optimal actions to be
selected without having to know anything about possible successor states and
their values, that is, without having to know anything about the environment's
dynamics.
Example 3.11: Bellman Optimality Equations for the Recycling Robot Using (3.15), we can explicitly give the the Bellman optimality equation for the recycling robot example. To make things more compact, we abbreviate the states high and low, and the actions search, wait, and recharge respectively by h, l, s, w, and re. Since there are only two states, the Bellman optimality equation consists of two equations. The equation for
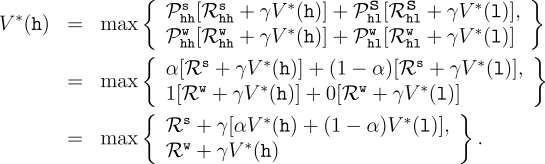
|
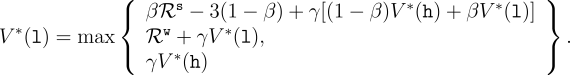
|
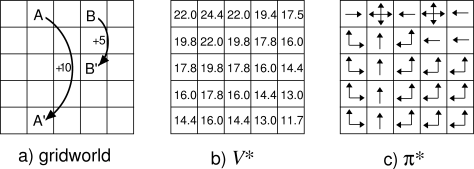
Example 3.12: Solving the Gridworld Suppose we solve the Bellman equation for
Explicitly solving the Bellman optimality equation
provides one route to finding an optimal policy, and thus to solving the
reinforcement learning problem. However, this solution is rarely directly useful.
It is akin to an exhaustive search, looking ahead at all possibilities, computing
their probabilities of occurrence and their desirabilities in terms of expected
rewards. This solution relies on at least three assumptions that are rarely true
in practice: (1) we accurately know the dynamics of the environment; (2) we have
enough computational resources to complete the computation of the solution; and
(3) the Markov property. For the kinds of tasks in which we are interested, one
is generally not able to implement this solution exactly because various
combinations of these assumptions are violated. For example, although the first
and third assumptions present no problems for the game of backgammon, the second
is a major impediment. Since the game has about
![]() states, it would take thousands of years on today's fastest computers to
solve the Bellman equation for
states, it would take thousands of years on today's fastest computers to
solve the Bellman equation for ![]() , and the same is true for
finding
, and the same is true for
finding ![]() . In reinforcement learning one typically has to settle for
approximate solutions.
. In reinforcement learning one typically has to settle for
approximate solutions.
Many different decision-making methods can be viewed as
ways of approximately solving the Bellman optimality equation. For example, heuristic
search methods can be viewed as expanding the right-hand side of
(3.15) several times, up to some depth, forming a
"tree'' of possibilities, and then using a heuristic evaluation function to
approximate ![]() at the "leaf'' nodes. (Heuristic search methods such as
at the "leaf'' nodes. (Heuristic search methods such as ![]() are almost always based on the episodic case.) The methods of
dynamic programming can be related even more closely to the Bellman optimality
equation. Many reinforcement learning methods can be clearly understood as
approximately solving the Bellman optimality equation, using actual experienced
transitions in place of knowledge of the expected transitions. We consider a
variety of such methods in the following chapters.
are almost always based on the episodic case.) The methods of
dynamic programming can be related even more closely to the Bellman optimality
equation. Many reinforcement learning methods can be clearly understood as
approximately solving the Bellman optimality equation, using actual experienced
transitions in place of knowledge of the expected transitions. We consider a
variety of such methods in the following chapters.
Exercise 3.14 Draw or describe the optimal state-value function for the golf example.
Exercise 3.15 Draw or describe the contours of the optimal action-value function for putting,
Exercise 3.16 Give the Bellman equation for
Exercise 3.17 Figure 3.8 gives the optimal value of the best state of the gridworld as 24.4, to one decimal place. Use your knowledge of the optimal policy and (3.2) to express this value symbolically, and then to compute it to three decimal places.