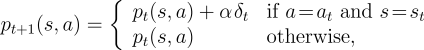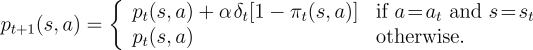


Next: 7.8 Replacing Traces
Up: 7. Eligibility Traces
Previous: 7.6 Q( )
Contents
)
Contents
In this section we describe how to extend the actor-critic methods
introduced in Section 6.6 to use eligibility traces.
This is fairly straightforward.
The critic part of an actor-critic method is simply on-policy
learning of 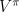 . The TD(
. The TD(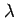 ) algorithm can be used for that, with one
eligibility trace for each state. The actor part needs to use an eligibility trace
for each state-action pair. Thus, an actor-critic method needs two sets of traces,
one for each state and one for each state-action pair.
) algorithm can be used for that, with one
eligibility trace for each state. The actor part needs to use an eligibility trace
for each state-action pair. Thus, an actor-critic method needs two sets of traces,
one for each state and one for each state-action pair.
Recall that the one-step actor-critic method updates the
actor by
where 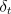 is the TD() error (7.6), and
is the TD() error (7.6), and
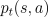 is the preference for taking action
is the preference for taking action  at time
at time  if in state
if in state  . The preferences determine the policy via, for example, a
softmax method (Section 2.3). We generalize the
above equation to use eligibility traces as follows:
. The preferences determine the policy via, for example, a
softmax method (Section 2.3). We generalize the
above equation to use eligibility traces as follows:
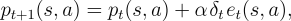
| (7.14) |
where 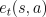 denotes the trace at time
denotes the trace at time  for state-action pair
for state-action pair
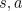 . For the simplest case mentioned above, the trace can be
updated as in Sarsa().
. For the simplest case mentioned above, the trace can be
updated as in Sarsa().
In Section 6.6 we also
discussed a more sophisticated actor-critic method that uses the
update
To generalize this equation to eligibility traces we can use the
same update (7.14) with a slightly different
trace. Rather than incrementing the trace by 1 each time a
state-action pair occurs, it is updated by 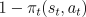 :
:
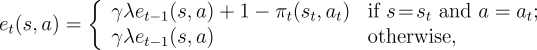
| (7.15) |
for all 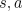 .
.
Next: 7.8 Replacing Traces
Up: 7. Eligibility Traces
Previous: 7.6 Q()
Contents
Mark Lee
2005-01-04