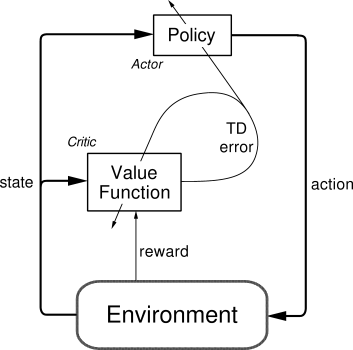
Actor-critic methods are TD methods that have a separate memory structure to explicitly represent the policy independent of the value function. The policy structure is known as the actor, because it is used to select actions, and the estimated value function is known as the critic, because it criticizes the actions made by the actor. Learning is always on-policy: the critic must learn about and critique whatever policy is currently being followed by the actor. The critique takes the form of a TD error. This scalar signal is the sole output of the critic and drives all learning in both actor and critic, as suggested by Figure 6.15.
Actor-critic methods are the natural extension of the idea of reinforcement comparison methods (Section 2.8) to TD learning and to the full reinforcement learning problem. Typically, the critic is a state-value function. After each action selection, the critic evaluates the new state to determine whether things have gone better or worse than expected. That evaluation is the TD error:
where ![]() is the current value function implemented by the critic. This TD error
can be used to evaluate the action just selected, the action
is the current value function implemented by the critic. This TD error
can be used to evaluate the action just selected, the action ![]() taken in
state
taken in
state ![]() . If the TD error is positive, it suggests that the tendency to
select
. If the TD error is positive, it suggests that the tendency to
select ![]() should be strengthened for the future, whereas if the TD error is
negative, it suggests the tendency should be weakened. Suppose actions are
generated by the Gibbs softmax method:
should be strengthened for the future, whereas if the TD error is
negative, it suggests the tendency should be weakened. Suppose actions are
generated by the Gibbs softmax method:
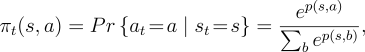
|
where the ![]() are the values at time
are the values at time ![]() of the modifiable policy
parameters of the actor, indicating the tendency to select (preference
for) each action
of the modifiable policy
parameters of the actor, indicating the tendency to select (preference
for) each action ![]() when in each state
when in each state ![]() . Then the strengthening or
weakening described above can be
implemented by increasing or decreasing
. Then the strengthening or
weakening described above can be
implemented by increasing or decreasing ![]() , for instance, by
, for instance, by
This is just one example of an actor-critic method. Other variations select the
actions in different ways, or use eligibility traces like those described in the
next chapter. Another common dimension of variation, as in
reinforcement comparison methods, is to include additional factors varying the
amount of credit assigned to the action taken, ![]() . For example, one of the
most common such factors is inversely related to the probability of selecting
. For example, one of the
most common such factors is inversely related to the probability of selecting
![]() , resulting in the update rule:
, resulting in the update rule:
Many of the earliest reinforcement learning systems that used TD methods were actor-critic methods (Witten, 1977; Barto, Sutton, and Anderson, 1983). Since then, more attention has been devoted to methods that learn action-value functions and determine a policy exclusively from the estimated values (such as Sarsa and Q-learning). This divergence may be just historical accident. For example, one could imagine intermediate architectures in which both an action-value function and an independent policy would be learned. In any event, actor-critic methods are likely to remain of current interest because of two significant apparent advantages:
In addition, the separate actor in actor-critic methods makes them more appealing in some respects as psychological and biological models. In some cases it may also make it easier to impose domain-specific constraints on the set of allowed policies.