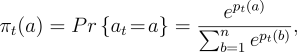A central intuition underlying reinforcement learning is that actions followed by large rewards should be made more likely to recur, whereas actions followed by small rewards should be made less likely to recur. But how is the learner to know what constitutes a large or a small reward? If an action is taken and the environment returns a reward of 5, is that large or small? To make such a judgment one must compare the reward with some standard or reference level, called the reference reward. A natural choice for the reference reward is an average of previously received rewards. In other words, a reward is interpreted as large if it is higher than average, and small if it is lower than average. Learning methods based on this idea are called reinforcement comparison methods. These methods are sometimes more effective than action-value methods. They are also the precursors to actor-critic methods, a class of methods for solving the full reinforcement learning problem that we present later.
Reinforcement comparison methods typically do not maintain estimates of action
values, but only of an overall reward level. In order to pick among the
actions, they maintain a separate measure of their preference for each action.
Let us denote the preference for action ![]() on play
on play ![]() by
by ![]() . The
preferences might be used to determine action-selection probabilities according
to a softmax relationship, such as
. The
preferences might be used to determine action-selection probabilities according
to a softmax relationship, such as
The reference reward is an incremental average of all
recently received rewards, whichever actions were taken. After the update
(2.10), the reference reward is updated:
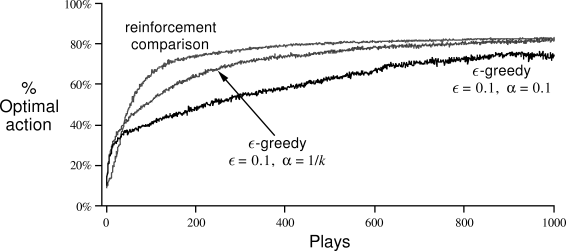
Reinforcement comparison methods can be very effective, sometimes performing even
better than action-value methods. Figure
2.5 shows the
performance of the above algorithm (![]() ) on the 10-armed
testbed. The performances of
) on the 10-armed
testbed. The performances of ![]() -greedy (
-greedy (![]() )
action-value methods with
)
action-value methods with ![]() and
and ![]() are also shown
for comparison.
are also shown
for comparison.
Exercise 2.9 The softmax action-selection rule given for reinforcement comparison methods (2.9) lacks the temperature parameter,
Exercise 2.10 The reinforcement comparison methods described here have two step-size parameters,
Exercise 2.11 (programming) Suppose the initial reference reward,