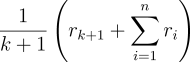The action-value methods we have discussed so far all estimate action
values as sample averages of observed rewards.
The obvious implementation is to maintain, for each action ![]() , a record of all
the rewards that have followed the selection of that action. Then, when
the estimate of the value of action a is needed at time
, a record of all
the rewards that have followed the selection of that action. Then, when
the estimate of the value of action a is needed at time ![]() , it can be computed
according to (2.1), which we repeat here:
, it can be computed
according to (2.1), which we repeat here:
As you might suspect, this is not really necessary. It is easy to devise
incremental update formulas for computing averages with small, constant
computation required to process each new reward. For some action, let ![]() denote
the average of its first
denote
the average of its first ![]() rewards (not to be confused with
rewards (not to be confused with ![]() , the
average for action
, the
average for action ![]() at the
at the ![]() th play). Given this average and a
th play). Given this average and a
![]() st reward,
st reward,
![]() , then the average of all
, then the average of all ![]() rewards can be computed by
rewards can be computed by
The update rule (2.4) is of a form that
occurs frequently throughout this book. The general form is
Note that the step-size parameter (![]() ) used in the incremental
method described above changes from time step to time step. In processing the
) used in the incremental
method described above changes from time step to time step. In processing the
![]() th reward for action
th reward for action
![]() , that method uses a step-size parameter of
, that method uses a step-size parameter of ![]() . In this book we
denote the step-size parameter by the symbol
. In this book we
denote the step-size parameter by the symbol ![]() or, more generally, by
or, more generally, by
![]() . For example, the above incremental implementation of the
sample-average method is described by the equation
. For example, the above incremental implementation of the
sample-average method is described by the equation
![]() . Accordingly, we sometimes use the informal shorthand
. Accordingly, we sometimes use the informal shorthand
![]() to refer to this case, leaving the action dependence implicit.
to refer to this case, leaving the action dependence implicit.
Exercise 2.5 Give pseudocode for a complete algorithm for the