


In this chapter we have become familiar with the basic ideas and algorithms of dynamic programming as they relate to solving finite MDPs. Policy evaluation refers to the (typically) iterative computation of the value functions for a given policy. Policy improvement refers to the computation of an improved policy given the value function for that policy. Putting these two computations together we obtain policy iteration and value iteration, the two most popular DP methods. Either of these can be used to reliably compute optimal policies and value functions for finite MDPs given complete knowledge of the MDP.
Classical DP methods operate in sweeps through the state set, performing a
full backup operation on each state. Each backup updates the value of one state
based on the value of all possible successor states and their probability of
occurring. Full backups are very closely related to Bellman equations: they
are little more than these equations turned into assignment statements. When the
backups no longer result in any changes in value, convergence has occurred to
values that satisfy the corresponding Bellman equation. Just as
there are four primary value functions (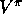 ,
, 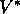 ,
, 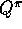 , and
, and 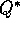 ),
there are four corresponding Bellman equations and four corresponding full
backups. An intuitive view of the operation of backups is given by backup
diagrams.
),
there are four corresponding Bellman equations and four corresponding full
backups. An intuitive view of the operation of backups is given by backup
diagrams.
Insight into DP methods, and, in fact, into almost all reinforcement learning methods, can be gained by viewing them as generalized policy iteration (GPI). GPI is the general idea of two interacting convergence processes revolving around an approximate policy and an approximate value function. One process takes the policy as given and performs some form of policy evaluation, changing the value function to be more like the true value function for the policy. The other process takes the value function as given and performs some form of policy improvement, changing the policy to make it better, assuming that the value function is its value function. Although each process changes the basis for the other, overall they work together to find a joint solution: a policy and value function that are unchanged by either process, and which, consequently, are optimal. In some cases, GPI can be proven to converge, most notably for the classical DP methods that we have presented in this chapter. In other cases convergence has not been proven, but still the idea of GPI improves our understanding of the methods.
It is not necessary to perform DP methods in complete sweeps through the state set. Asynchronous DP methods are in-place iterative methods that backup states in an arbitrary order, perhaps stochastically determined and using out of date information. Many of these methods can be viewed as fine-grained forms of GPI.
Finally, we note one last special property of DP methods. All of them update their estimates of the value of a state based on estimates of the successor states of that state. That is, they update one estimate based on another estimate. We call this general idea bootstrapping. Many reinforcement learning methods perform bootstrapping, even those that do not require, as DP requires, a complete and accurate model of the environment. In the next chapter we explore reinforcement learning methods that do not require a model and do not bootstrap. In the following chapter we explore methods that do not require a model but do bootstrap. These key features and properties are separable, yet can be mixed together in many interesting combinations.