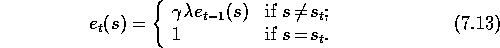In some cases significantly better performance can be obtained by using a slightly modified kind of trace known as a replacing trace. Suppose a state is visited and then revisited before the trace due to the first visit has fully decayed to zero. With accumulating traces (7.5), the revisit causes a further increment in the trace, driving it greater than 1, whereas with replacing traces, the trace is reset to 1. Figure 7.16 contrasts these two kinds of traces. Formally, a replacing trace for a discrete state s is defined by
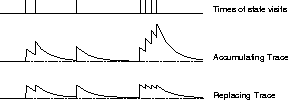
Figure 7.16: Accumulating and replacing traces.
Prediction or control algorithms using replacing traces are often called
replace-trace methods. Although
replacing traces are only slightly different from accumulating traces, they can
produce a significant improvement in learning rate. Figure 7.17
compares the performance of conventional and replace-trace versions of TD(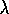 )
on the
19-state random-walk prediction task.
Other examples for a slightly more general
case are given in Figure 8 .10
in the next chapter.
)
on the
19-state random-walk prediction task.
Other examples for a slightly more general
case are given in Figure 8 .10
in the next chapter.
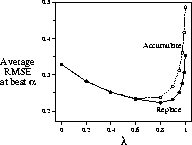
Figure 7.17: Error as a function of 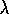 on a 19-state random walk
process. These data are using the best value of
on a 19-state random walk
process. These data are using the best value of 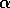 for each value of
for each value of 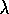 .
.
Example 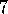 .
.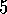
Figure 7.18 shows an example of the kind of task that is difficult for
control methods using accumulating eligibility traces. All rewards are zero except
on entering the terminal state for a reward of +1. From each state, selecting the
right action brings the agent one step closer to the terminal reward,
whereas the wrong (upper) action leaves it in the same state to try again.
The full sequence of states is long enough that one would like to use long traces
to get the fastest learning. However, problems occur if long accumulating traces
are used. Suppose, on the first episode, at some state, s, the agent by chance
takes the wrong action a few times before taking the right action.
As the agent continues, the trace
 is likely to be larger than the trace
is likely to be larger than the trace 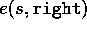 . The right action was more recent, but the
wrong action was selected more times. When reward is finally received, then,
the value for the wrong action is likely to go up more than for the right action.
On the next episode the agent will be even more likely to go the wrong way
many times before going right, making it even more likely that the
wrong action will have the larger trace. Eventually, all of this will be
corrected, but learning is significantly slowed. With replacing traces, on the
other hand, this problem never occurs. No matter how many times the
wrong action is taken, its eligibility trace is always less than that for
the right action after the right action has been taken.
. The right action was more recent, but the
wrong action was selected more times. When reward is finally received, then,
the value for the wrong action is likely to go up more than for the right action.
On the next episode the agent will be even more likely to go the wrong way
many times before going right, making it even more likely that the
wrong action will have the larger trace. Eventually, all of this will be
corrected, but learning is significantly slowed. With replacing traces, on the
other hand, this problem never occurs. No matter how many times the
wrong action is taken, its eligibility trace is always less than that for
the right action after the right action has been taken.
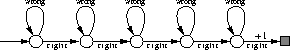
Figure 7.18: A simple task that causes problems for control methods using
accumulating traces.
There is an interesting relationship between the replace-trace methods and Monte Carlo methods in the undiscounted case. Just as conventional TD(1) is related to the every-visit MC algorithm, replace-trace TD(1) is related to the first-visit MC algorithm. In particular, the offline version of replace-trace TD(1) is formally identical to first-visit MC (Singh and Sutton, 1996). How, or even whether, these methods and results extend to the discounted case is unknown.
There are several possible ways to generalize replacing eligibility traces for use in control methods. Obviously, when a state is re-visited and a new action selected, the trace for that action should be reset to 1. But what of the traces for the other actions for that state? The approach recommended by Singh and Sutton (1996) is to set the traces of all the other actions from the re-visited state to 0. In this case, the state-action traces are updated by the following instead of (7.10):
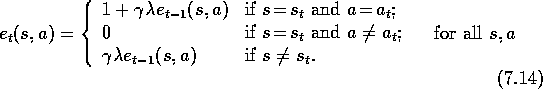
Note that this variant of replacing traces works out even better than the original replacing traces in the example task. Once the right action has been selected, the wrong action is left with no trace at all. The results shown in Figure 8 .10 were all obtained using this kind of replacing trace.
Exercise  .
.
In Example  .
.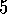 , suppose from state s the wrong action is
taken twice before the right action is taken. If accumulating traces
are used, then how big must the trace parameter
, suppose from state s the wrong action is
taken twice before the right action is taken. If accumulating traces
are used, then how big must the trace parameter 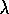 be in order for the wrong
action to end up with a larger eligibility trace than the right action?
be in order for the wrong
action to end up with a larger eligibility trace than the right action?
Exercise 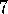 .
.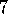 (programming)
(programming)
Program Example 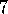 .
.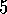 and compare
accumulate-trace and replace-trace versions of Sarsa(
and compare
accumulate-trace and replace-trace versions of Sarsa(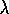 )
on it, for
)
on it, for 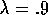 and
a range of
and
a range of 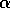 values. Can you empirically demonstrate the claimed advantage
of replacing traces on this example?
values. Can you empirically demonstrate the claimed advantage
of replacing traces on this example?
Exercise 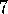 .
.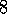 *
*
Draw a backup diagram for Sarsa(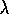 )
with replacing traces.
)
with replacing traces.