


The reinforcement learning problem is meant to be a straightforward framing of the
problem of learning from interaction to achieve a goal. The learner and decision-maker
is called the agent. The thing it interacts with, comprising everything outside
the agent, is called the environment. These interact continually, the agent
selecting actions and the environment responding to those actions and presenting new
situations to the agent.
The environment also gives rise to rewards, a special signal whose values the agent tries to maximize over time. A complete specification of an environment defines a task, one instance of the reinforcement learning problem.
More specifically, the agent and environment interact at each of a sequence of
discrete time steps, 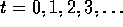 .
At each time step,
t, the agent receives some representation of the environment's state,
.
At each time step,
t, the agent receives some representation of the environment's state,
 , where
, where 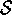 is the set of possible states, and on that basis selects
an action,
is the set of possible states, and on that basis selects
an action, 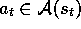 , where
, where
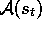 is the set of actions available in state
is the set of actions available in state 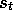 . One time step later, in
part as a consequence of its action, the agent receives a numerical reward,
. One time step later, in
part as a consequence of its action, the agent receives a numerical reward,
 , and finds itself in a new state,
, and finds itself in a new state, 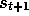 .
.
Figure 3.1 diagrams the agent-environment interaction.
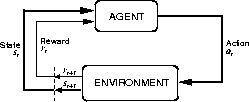
Figure 3.1: The reinforcement learning framework
At each time step, the agent implements a mapping from state representations
to probabilities of selecting each possible action. This mapping is
called the agent's policy and denoted 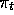 , where
, where 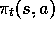 is the
probability that
is the
probability that 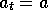 if
if
 . Reinforcement learning methods specify how the agent changes its policy as
a result of its experience. The agent's goal, roughly speaking, is to maximize the
total amount of reward it receives over the long run.
. Reinforcement learning methods specify how the agent changes its policy as
a result of its experience. The agent's goal, roughly speaking, is to maximize the
total amount of reward it receives over the long run.
This framework is abstract and very flexible, allowing it be applied to many different problems in many different ways. For example, the time steps need not refer to fixed intervals of real time; they can refer to arbitrary successive stages of decision making and acting. The actions can be low-level controls such as the voltages applied to the motors of a robot arm, or high-level decisions such as whether or not to have lunch or to go to graduate school. Similarly, the states can take a wide variety of forms. They can be completely determined by low-level sensations, such as direct sensor readings, or they can be more high-level and abstract, such as symbolic descriptions of objects in a room. Some of what makes up a state could be based on memory of past sensations or even be entirely mental or subjective. For example, an agent could be in ``the state" of not being sure where an object is, or of having just been ``surprised" in some clearly defined sense. Similarly, some actions might be totally mental or computational. For example, some actions might control what an agent chooses to think about, or where it focuses its attention. In general, actions can be any decisions we want to learn how to make, and the state representations can be anything we can know that might be useful in making them.
In particular, it is a mistake to think of the interface between the agent and the environment as the physical boundary of a robot's or animal's body. Usually, the boundary is drawn closer to the agent than that. For example, the motors and mechanical linkages of a robot and its sensing hardware should usually be considered parts of the environment rather than parts of the agent. Similarly, if we apply the framework to a person or animal, the muscles, skeleton, and sensory organs should all be considered part of the environment. Rewards too are presumably computed inside the physical bodies of natural and artificial learning systems, but are considered external to the agent.
The general rule we follow is that anything that cannot be changed arbitrarily by the agent is considered to be outside of it and thus part of its environment. We do not assume that everything in the environment is unknown to the agent. For example, the agent often knows quite a bit about how its rewards are computed as a function of its actions and the states in which they are taken. But we always consider the reward computation to be external to the agent because it defines the task facing the agent and thus must be beyond its ability to change arbitrarily. In fact, in some cases the agent may know everything about how its environment works and still face a difficult reinforcement learning task, just as we may know exactly how a puzzle like Rubik's cube works, but still be unable to solve it. The agent-environment boundary represents the limit of the agent's absolute control, not of its knowledge.
The agent-environment boundary can be placed at different places for different purposes. In a complicated robot, many different agents may be operating at once, each with its own boundary. For example, one agent may make high-level decisions which form part of the states faced by a lower-level agent that implements the high-level decisions. In practice, the agent-environment boundary is determined once one has selected particular states, actions, and rewards, and thus identified a specific decision-making task of interest.
The reinforcement learning framework is a considerable abstraction of the problem of goal-directed learning from interaction. It proposes that whatever the details of the sensory, memory, and control apparatus, and whatever objective one is trying to achieve, any problem of learning goal-directed behavior can be reduced to three signals passing back and forth between an agent and its environment: one signal to represent the choices made by the agent (the actions), one signal to represent the basis on which the choices are made (the states), and one signal to define the agent's goal (the rewards). This framework may not be sufficient to usefully represent all decision-learning problems, but it has proven itself widely useful and applicable.
Of course, the state and action representations vary greatly from application to application and strongly affect performance. In reinforcement learning, as in other kinds of learning, such representational choices are at present more art than science. In this book we offer some advice and examples regarding good choices of state and action representations, but our primary focus is on the general principles useful for learning how to behave once the state and action representations have been selected.
Example 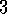 .
.
Bioreactor.
Suppose reinforcement learning is being applied to determine moment-by-moment
temperatures and stirring rates for a bioreactor (a large vat of nutrients and
bacteria used to produce useful chemicals). The actions in such an application might
be target temperatures and target stirring rates that are passed to
lower-level control systems which, in turn, directly activate heating elements and
motors to attain the targets. The state representation is likely to be
thermocouple and other sensory readings, perhaps filtered and delayed, plus symbolic
inputs representing the ingredients in the vat and the target chemical.
The reward might be a moment-by-moment measure of the rate at which the useful
chemical is produced by the bioreactor. Notice that here each state
representation is a list, or vector, of sensor readings and symbolic inputs,
and each action is a vector consisting of a target temperature and a stirring
rate. It is typical of reinforcement learning tasks to have such state and
action representations with this kind of structure. Rewards, on the other
hand, are always single numbers.

Example 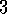 .
.
Pick-and-Place Robot.
Consider using reinforcement learning to control the motion of a
robot arm in a repetitive pick-and-place task. If we want to learn
movements that are fast and smooth, the learning agent will have to
directly control the motors and have low-latency information about the current
positions and velocities of the mechanical linkages. The actions in this case might
be the currents applied to each motor at each joint, and the state representation
might be the latest readings of joint angles and velocities. The reward might be
simply +1 for each object successfully picked up and placed. To encourage
smooth movements, on each time step a small, negative reward can be given
dependent on a measure of the moment-to-moment ``jerkiness" of the motion.

Example  .
.
Recycling Robot.
A mobile robot has the job of collecting empty soda cans in an office environment.
It has sensors for detecting cans, an arm and gripper that that can pick them up
and place them in an onboard bin, and it runs on rechargable batteries. The robot's
control system has components for interpreting sensory information, for navigating, and
for controlling the arm and gripper. High-level decisions about how to search for cans
are made by a reinforcement learning agent on the basis of the current charge level
of the battery. This agent has to decide whether the robot should 1) actively
search for a can for a certain period of time, 2) remain stationary and wait for someone
to bring it a can, or 3) head back to its home base to recharge its batteries. This
decision has to be made either periodically or whenever certain events occur, such as
finding an empty can. The agent therefore has three actions, and its state is
determined by the state of the battery. The rewards might be zero most of the time, but
then become positive when the robot secures an empty can, or large and negative if the
battery runs all the way down. In this example, the reinforcement learning agent is not
the entire robot. The states it monitors describe conditions within the robot
itself, not conditions of the robot's external environment. The agent's environment
therefore includes the rest of the robot, which might contain other complex
decision-making systems, as well as the robot's external environment.

Exercise  .
.
Devise three example tasks of your own that fit into the reinforcement learning framework, identifying for each its state representations, actions, and rewards. Make the three examples as different from each other as possible. The framework is very abstract and flexible and can be applied in many different ways. Stretch its limits in some way in at least one of your examples.
Exercise  .
.
Is the reinforcement learning framework adequate to usefully represent all goal-directed learning tasks? Can you think of any clear exceptions?
Exercise  .
.
Consider the problem of driving. You could define the actions in terms of the accelerator, steering wheel, and brake, i.e., where your body meets the machine. Or you could define them farther out, say where the rubber meets the road, considering your actions to be tire torques. Or, you could define them farther in, say where your brain meets your body, the actions being muscle twitches to control your limbs. Or you could go to a really high level and say that your actions are your choices of where to drive. What is the right level, the right place to draw the line between agent and environment? On what basis is one location of the line to be preferred over another? Is there any fundamental reason for preferring one location over another, or is it just a free choice?