


Next: Summary of Notation
Up: Contents
Previous: 11 Case Studies
References
- Agre, 1988
-
Agre, P. E. (1988).
The Dynamic Structure of Everyday Life.
PhD thesis, Massachusetts Institute of Technology, Cambridge, MA.
AI-TR 1085, MIT Artificial Intelligence Laboratory.
- Agre and Chapman, 1990
-
Agre, P. E. and Chapman, D. (1990).
What are plans for?
Robotics and Autonomous Systems, 6:17--34.
- Albus, 1971
-
Albus, J. S. (1971).
A theory of cerebellar function.
Mathematical Biosciences, 10:25--61.
- Albus, 1981
-
Albus, J. S. (1981).
Brain, Behavior, and Robotics.
Byte Books.
- Anderson, 1986
-
Anderson, C. W. (1986).
Learning and Problem Solving with Multilayer Connectionist
Systems.
PhD thesis, University of Massachusetts, Amherst, MA.
- Anderson, 1987
-
Anderson, C. W. (1987).
Strategy learning with multilayer connectionist representations.
Technical Report TR87-509.3, GTE Laboratories, Incorporated, Waltham,
MA.
(This is a corrected version of the report published in
Proceedings of the Fourth International Workshop on Machine
Learning,103--114, 1987, San Mateo, CA: Morgan Kaufmann.).
- Anderson et al., 1977
-
Anderson, J. A., Silversten, J. W., Ritz, S. A., and Jones, R. S. (1977).
Distinctive features, categorical perception, and probability
learning: Some applications of a neural model.
Psychological Review, 84:413--451.
- Andreae, 1963
-
Andreae, J. H. (1963).
STELLA: A scheme for a learning machine.
In Proceedings of the 2nd IFAC Congress, Basle, pages 497--502,
London. Butterworths.
- Andreae, 1969a
-
Andreae, J. H. (1969a).
A learning machine with monologue.
International Journal of Man-Machine Studies, 1:1--20.
- Andreae, 1969b
-
Andreae, J. H. (1969b).
Learning machines---a unified view.
In Meetham, A. R. and Hudson, R. A., editors, Encyclopedia of
Information, Linguistics, and Control, pages 261--270. Pergamon, Oxford.
- Andreae, 1977
-
Andreae, J. H. (1977).
Thinking with the Teachable Machine.
Academic Press, London.
- Baird, 1995
-
Baird, L. C. (1995).
Residual algorithms: Reinforcement learning with function
approximation.
In Prieditis, A. and Russell, S., editors, Proceedings of the
Twelfth International Conference on Machine Learning, pages 30--37, San
Francisco, CA. Morgan Kaufmann.
- Bao et al., 1994
-
Bao, G., Cassandras, C. G., Djaferis, T. E., Gandhi, A. D., and Looze, D. P.
(1994).
Elevator dispatchers for down peak traffic.
Technical report, ECE Department, University of Massachusetts.
- Barnard, 1993
-
Barnard, E. (1993).
Temporal-difference methods and Markov models.
IEEE Transactions on Systems, Man, and Cybernetics,
23:357--365.
- Barto, 1985
-
Barto, A. G. (1985).
Learning by statistical cooperation of self-interested neuron-like
computing elements.
Human Neurobiology, 4:229--256.
- Barto, 1986
-
Barto, A. G. (1986).
Game-theoretic cooperativity in networks of self-interested units.
In Denker, J. S., editor, Neural Networks for Computing, pages
41--46. American Institute of Physics, New York.
- Barto, 1990
-
Barto, A. G. (1990).
Connectionist learning for control: An overview.
In Miller, T., Sutton, R. S., and Werbos, P. J., editors, Neural
Networks for Control, pages 5--58. MIT Press, Cambridge, MA.
- Barto, 1991
-
Barto, A. G. (1991).
Some learning tasks from a control perspective.
In Nadel, L. and Stein, D. L., editors, 1990 Lectures in Complex
Systems, pages 195--223. Addison-Wesley Publishing Company, The Advanced
Book Program, Redwood City, CA.
- Barto, 1992
-
Barto, A. G. (1992).
Reinforcement learning and adaptive critic methods.
In White, D. A. and Sofge, D. A., editors, Handbook of
Intelligent Control: Neural, Fuzzy, and Adaptive Approaches, pages
469--491. Van Nostrand Reinhold, New York.
- Barto, 1995a
-
Barto, A. G. (1995a).
Adaptive critics and the basal ganglia.
In Houk, J. C., Davis, J. L., and Beiser, D. G., editors, Models
of Information Processing in the Basal Ganglia, pages 215--232. MIT Press,
Cambridge, MA.
- Barto, 1995b
-
Barto, A. G. (1995b).
Reinforcement learning.
In Arbib, M. A., editor, Handbook of Brain Theory and Neural
Networks, pages 804--809. The MIT Press, Cambridge, MA.
- Barto and Anandan, 1985
-
Barto, A. G. and Anandan, P. (1985).
Pattern recognizing stochastic learning automata.
IEEE Transactions on Systems, Man, and Cybernetics,
15:360--375.
- Barto and Anderson, 1985
-
Barto, A. G. and Anderson, C. W. (1985).
Structural learning in connectionist systems.
In Program of the Seventh Annual Conference of the Cognitive
Science Society, pages 43--54, Irvine, CA.
- Barto et al., 1982
-
Barto, A. G., Anderson, C. W., and Sutton, R. S. (1982).
Synthesis of nonlinear control surfaces by a layered associative
search network.
Biological Cybernetics, 43:175--185.
- Barto et al., 1991
-
Barto, A. G., Bradtke, S. J., and Singh, S. P. (1991).
Real-time learning and control using asynchronous dynamic
programming.
Technical Report 91-57, Department of Computer and Information
Science, University of Massachusetts, Amherst, MA.
- Barto et al., 1995
-
Barto, A. G., Bradtke, S. J., and Singh, S. P. (1995).
Learning to act using real-time dynamic programming.
Artificial Intelligence, 72:81--138.
- Barto and Duff, 1994
-
Barto, A. G. and Duff, M. (1994).
Monte carlo matrix inversion and reinforcement learning.
In Cohen, J. D., Tesauro, G., and Alspector, J., editors,
Advances in Neural Information Processing Systems: Proceedings of the 1993
Conference, pages 687--694, San Francisco, CA. Morgan Kaufmann.
- Barto and Jordan, 1987
-
Barto, A. G. and Jordan, M. I. (1987).
Gradient following without back-propagation in layered networks.
In Caudill, M. and Butler, C., editors, Proceedings of the
IEEE First Annual Conference on Neural Networks, pages II629--II636, San
Diego, CA.
- Barto and Sutton, 1981a
-
Barto, A. G. and Sutton, R. S. (1981a).
Goal seeking components for adaptive intelligence: An initial
assessment.
Technical Report AFWAL-TR-81-1070, Air Force Wright Aeronautical
Laboratories/Avionics Laboratory, Wright-Patterson AFB, OH.
- Barto and Sutton, 1981b
-
Barto, A. G. and Sutton, R. S. (1981b).
Landmark learning: An illustration of associative search.
Biological Cybernetics, 42:1--8.
- Barto and Sutton, 1982
-
Barto, A. G. and Sutton, R. S. (1982).
Simulation of anticipatory responses in classical conditioning by a
neuron-like adaptive element.
Behavioural Brain Research, 4:221--235.
- Barto et al., 1983
-
Barto, A. G., Sutton, R. S., and Anderson, C. W. (1983).
Neuronlike elements that can solve difficult learning control
problems.
IEEE Transactions on Systems, Man, and Cybernetics,
13:835--846.
Reprinted in J. A. Anderson and E. Rosenfeld, Neurocomputing:
Foundations of Research, MIT Press, Cambridge, MA, 1988.
- Barto et al., 1981
-
Barto, A. G., Sutton, R. S., and Brouwer, P. S. (1981).
Associative search network: A reinforcement learning associative
memory.
IEEE Transactions on Systems, Man, and Cybernetics,
40:201--211.
- Bellman and Dreyfus, 1959
-
Bellman, R. and Dreyfus, S. E. (1959).
Functional approximations and dynamic programming.
Math Tables and Other Aides to Computation, 13:247--251.
- Bellman et al., 1973
-
Bellman, R., Kalaba, R., and Kotkin, B. (1973).
Polynomial approximation---A new computational technique in dynamic
programming: Allocation processes.
Mathematical Computation, 17:155--161.
- Bellman, 1956
-
Bellman, R. E. (1956).
A problem in the sequential design of experiments.
Sankhya, 16:221--229.
- Bellman, 1957a
-
Bellman, R. E. (1957a).
Dynamic Programming.
Princeton University Press, Princeton, NJ.
- Bellman, 1957b
-
Bellman, R. E. (1957b).
A Markov decision process.
Journal of Mathematical Mech., 6:679--684.
- Berry and Fristedt, 1985
-
Berry, D. A. and Fristedt, B. (1985).
Bandit Problems.
Chapman and Hall, London.
- Bertsekas, 1982
-
Bertsekas, D. P. (1982).
Distributed dynamic programming.
IEEE Transactions on Automatic Control, 27:610--616.
- Bertsekas, 1983
-
Bertsekas, D. P. (1983).
Distributed asynchronous computation of fixed points.
Mathematical Programming, 27:107--120.
- Bertsekas, 1987
-
Bertsekas, D. P. (1987).
Dynamic Programming: Deterministic and Stochastic Models.
Prentice-Hall, Englewood Cliffs, NJ.
- Bertsekas, 1995
-
Bertsekas, D. P. (1995).
Dynamic Programming and Optimal Control.
Athena, Belmont, MA.
- Bertsekas and Tsitsiklis, 1989
-
Bertsekas, D. P. and Tsitsiklis, J. N. (1989).
Parallel and Distributed Computation: Numerical Methods.
Prentice-Hall, Englewood Cliffs, NJ.
- Bertsekas and Tsitsiklis, 1996
-
Bertsekas, D. P. and Tsitsiklis, J. N. (1996).
Neural Dynamic Programming.
Athena Scientific, Belmont, MA.
- Biermann et al., 1982
-
Biermann, A. W., Fairfield, J. R. C., and Beres, T. R. (1982).
Signature table systems and learning.
IEEE Transactions on Systems, Man, and Cybernetics,
SMC-12:635--648.
- Bishop, 1995
-
Bishop, C. M. (1995).
Neural Networks for Pattern Recognition.
Clarendon, Oxford.
- Booker, 1982
-
Booker, L. B. (1982).
Intelligent Behavior as an Adaptation to the Task Environment.
PhD thesis, University of Michigan, Ann Arbor, MI.
- Boone, 1997
-
Boone, G. (1997).
Minimum-time control of the acrobot.
In 1997 International Conference on Robotics and Automation,
Albuquerque, NM.
- Boutilier et al., 1995
-
Boutilier, C., Dearden, R., and Goldszmidt, M. (1995).
Exploiting structure in policy construction.
In Proceedings of the Fourteenth International Joint Conference
on Artificial Intelligence.
- Boyan and Moore, 1995
-
Boyan, J. A. and Moore, A. W. (1995).
Generalization in reinforcement learning: Safely approximating the
value functions.
In G. Tesauro, D. Touretzky, T. L., editor, Advances in Neural
Information Processing Systems: Proceedings of the 1994 Conference, pages
369--376, San Mateo, CA. Morgan Kaufmann.
- Boyan et al., 1995
-
Boyan, J. A., Moore, A. W., and Sutton, R. S., editors (1995).
Proceedings of the Workshop on Value Function Approximation.
Machine Learning Conference 1995, Pittsburgh, PA. School of Computer
Science, Carnegie Mellon University.
Technical Report CMU-CS-95-206.
- Bradtke, 1993
-
Bradtke, S. J. (1993).
Reinforcement learning applied to linear quadratic regulation.
In S. J. Hanson, J. D. Cowan, C. L. G., editor, Advances in
Neural Information Processing Systems: Proceedings of the 1992 Conference,
pages 295--302, San Mateo, CA. Morgan Kaufmann.
- Bradtke, 1994
-
Bradtke, S. J. (1994).
Incremental Dynamic Programming for On-Line Adaptive Optimal
Control.
PhD thesis, University of Massachusetts, Amherst.
Appeared as CMPSCI Technical Report 94-62.
- Bradtke and Barto, 1996
-
Bradtke, S. J. and Barto, A. G. (1996).
Linear least--squares algorithms for temporal difference learning.
Machine Learning, 22:33--57.
- Bradtke and Duff, 1995
-
Bradtke, S. J. and Duff, M. O. (1995).
Reinforcement learning methods for continuous-time Markov decision
problems.
In G. Tesauro, D. Touretzky, T. L., editor, Advances in Neural
Information Processing Systems: Proceedings of the 1994 Conference, pages
393--400, San Mateo, CA. Morgan Kaufmann.
- Bridle, 1990
-
Bridle, J. S. (1990).
Training stochastic model recognition algorithms as networks can lead
to maximum mutual information estimates of parameters.
In Touretzky, D. S., editor, Advances in Neural Information
Processing Systems 2, pages 211--217, San Mateo, CA. Morgan Kaufmann.
- Broomhead and Lowe, 1988
-
Broomhead, D. S. and Lowe, D. (1988).
Multivariable functional interpolation and adaptive networks.
Complex Systems, 2:321--355.
- Bryson, 1996
-
Bryson, Jr., A. E. (1996).
Optimal control---1950 to 1985.
IEEE Control Systems, 13(3):26--33.
- Bush and Mosteller, 1955
-
Bush, R. R. and Mosteller, F. (1955).
Stochastic Models for Learning.
Wiley, New York.
- Byrne et al., 1990
-
Byrne, J. H., Gingrich, K. J., and Baxter, D. A. (1990).
Computational capabilities of single neurons: Relationship to
simple forms of associative and nonassociative learning in aplysia.
In Hawkins, R. D. and Bower, G. H., editors, Computational
Models of Learning, pages 31--63. Academic Press, New York.
- Campbell, 1959
-
Campbell, D. T. (1959).
Blind variation and selective survival as a general strategy in
knowledge-processes.
In Yovits, M. C. and Cameron, S., editors, Self-Organizing
Systems, pages 205--231. Pergamon.
- Carlström and Nordström, 1997
-
Carlström, J. and Nordström, E. (1997).
Control of self-similar atm call traffic by reinforcement learning.
In Proceedings of the International Workshop on Applications of
Neural Networks to Telecommunications 3 (IWANNT*97), Hillsdale NJ. Lawrence
Erlbaum.
- Chapman and Kaelbling, 1991
-
Chapman, D. and Kaelbling, L. P. (1991).
Input generalization in delayed reinforcement learning: An
algorithm and performance comparisons.
In Proceedings of the 1991 International Joint Conference on
Artificial Intelligence.
- Chow and Tsitsiklis, 1991
-
Chow, C.-S. and Tsitsiklis, J. N. (1991).
An optimal one-way multigrid algorithm for discrete-time stochastic
control.
IEEE Transactions on Automatic Control, 36:898--914.
- Chrisman, 1992
-
Chrisman, L. (1992).
Reinforcement learning with perceptual aliasing: The perceptual
distinctions approach.
In Proceedings of the Tenth National Conference on Artificial
Intelligence, pages 183--188, Menlo Park, CA. AAAI Press/MIT Press.
- Christensen and Korf, 1986
-
Christensen, J. and Korf, R. E. (1986).
A unified theory of heuristic evaluation functions and its
application to learning.
In Proceedings of the Fifth National Conference on Artificial
Intelligence AAAI-86, pages 148--152, San Mateo, CA. Morgan Kaufmann.
- Cichosz, 1995
-
Cichosz, P. (1995).
Truncating temporal differences: On the efficient implementation of
TD(lambda) for reinforcement learning.
Journal of Artificial Intelligence Research, 2:287--318.
- Clark and Farley, 1955
-
Clark, W. A. and Farley, B. G. (1955).
Generalization of pattern recognition in a self-organizing system.
In Proceedings of the 1955 Western Joint Computer Conference,
pages 86--91.
- Clouse, 1997
-
Clouse, J. (1997).
On Integrating Apprentice Learning and Reinforcement Learning
TITLE2.
PhD thesis, University of Massachusetts, Amherst.
Appeared as CMPSCI Technical Report 96-026.
- Clouse and Utgoff, 1992
-
Clouse, J. and Utgoff, P. (1992).
A teaching method for reinforcement learning systems.
In Proceedings of the Ninth International Machine Learning
Conference, pages 92--101.
- Colombetti and Dorigo, 1994
-
Colombetti, M. and Dorigo, M. (1994).
Training agent to perform sequential behavior.
Adaptive Behavior, 2(3):247--275.
- Connell, 1989
-
Connell, J. (1989).
A colony architecture for an artificial creature.
Technical Report Technical Report AI-TR-1151, MIT Artificial
Intelligence Laboratory, Cambridge, MA.
- Craik, 1943
-
Craik, K. J. W. (1943).
The Nature of Explanation.
Cambridge University Press, Cambridge.
- Crites, 1996
-
Crites, R. H. (1996).
Large-Scale Dynamic Optimization Using Teams of Reinforcement
Learning Agents.
PhD thesis, University of Massachusetts, Amherst, MA.
- Crites and Barto, 1996
-
Crites, R. H. and Barto, A. G. (1996).
Improving elevator performance using reinforcement learning.
In D. S. Touretzky, M. C. Mozer, M. E. H., editor, Advances in
Neural Information Processing Systems: Proceedings of the 1995 Conference,
pages 1017--1023, Cambridge, MA. MIT Press.
- Curtiss, 1954
-
Curtiss, J. H. (1954).
A theoretical comparison of the efficiencies of two classical methods
and a monte carlo method for computing one component of the solution of a set
of linear algebraic equations.
In Meyer, H. A., editor, Symposium on Monte Carlo Methods,
pages 191--233. Wiley, New York.
- Cziko, 1995
-
Cziko, G. (1995).
Without Miracles. Universal Selection Theory and the Second
Darvinian Revolution.
The MIT Press.
- Daniel, 1976
-
Daniel, J. W. (1976).
Splines and efficiency in dynamic programming.
Journal of Mathematical Analysis and Applications, 54:402--407.
- Dayan, 1991
-
Dayan, P. (1991).
Reinforcement comparison.
In Touretzky, D. S., Elman, J. L., Sejnowski, T. J., and Hinton,
G. E., editors, Connectionist Models: Proceedings of the 1990 Summer
School, pages 45--51. Morgan Kaufmann, San Mateo, CA.
- Dayan, 1992
-
Dayan, P. (1992).
The convergence of TD(
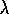 ) for general
) for general 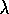 .
Machine Learning, 8:341--362.
.
Machine Learning, 8:341--362.
- Dayan and Hinton, 1993
-
Dayan, P. and Hinton, G. E. (1993).
Feudal reinforcement learning.
In Hanson, S. J., Cohen, J. D., and Giles, C. L., editors,
Advances in Neural Information Processing Systems: Proceedings of the 1992
Conference, pages 271--278, San Mateo, CA. Morgan Kaufmann.
- Dayan and Sejnowski, 1994
-
Dayan, P. and Sejnowski, T. (1994).
TD(
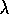 ) converges with probability 1.
Machine Learning, 14:295--301.
) converges with probability 1.
Machine Learning, 14:295--301.
- Dean and Lin, 1995
-
Dean, T. and Lin, S.-H. (1995).
Decomposition techniques for planning in stochastic domains.
In Proceedings of the Fourteenth International Joint Conference
on Artificial Intelligence.
- DeJong and Spong, 1994
-
DeJong, G. and Spong, M. W. (1994).
Swinging up the acrobot: An example of intelligent control.
In Proceedings of the American Control Conference, pages
2158--2162.
- Denardo, 1967
-
Denardo, E. V. (1967).
Contraction mappings in the theory underlying dynamic programming.
SIAM Review, 9:165--177.
- Dennett, 1978
-
Dennett, D. C. (1978).
Brainstorms, chapter Why the Law-of-Effect Will Not Go Away,
pages 71--89.
Bradford/MIT Press, Cambridge, MA.
- Dietterich and Flann, 1995
-
Dietterich, T. G. and Flann, N. S. (1995).
Explanation-based learning and reinforcement learning: A unified
view.
In Prieditis, A. and Russell, S., editors, Proceedings of the
Twelfth International Conference on Machine Learning, pages 176--184, San
Francisco, CA. Morgan Kaufmann.
- Doya, 1996
-
Doya, K. (1996).
Temporal difference learing in continuous time and space.
In Touretzky, D. S., Mozer, M. C., and Hasselmo, M. E., editors,
Advances in Neural Information Processing Systems: Proceedings of the 1995
Conference, pages 1073--1079, Cambridge, MA. MIT Press.
- Doyle and Snell, 1984
-
Doyle, P. G. and Snell, J. L. (1984).
Random Walks and Electric Networks.
The Mathematical Association of America.
Carus Mathematical Monograph 22.
- Dreyfus and Law, 1977
-
Dreyfus, S. E. and Law, A. M. (1977).
The Art and Theory of Dynamic Programming.
Academic Press, New York.
- Duda and Hart, 1973
-
Duda, R. O. and Hart, P. E. (1973).
Pattern Classification and Scene Analysis.
Wiley, New York.
- Duff, 1995
-
Duff, M. O. (1995).
Q-learning for bandit problems.
In Prieditis, A. and Russell, S., editors, Proceedings of the
Twelfth International Conference on Machine Learning, pages 209--217, San
Francisco, CA. Morgan Kaufmann.
- Estes, 1950
-
Estes, W. K. (1950).
Toward a statistical theory of learning.
Psychololgical Review, 57:94--107.
- Farley and Clark, 1954
-
Farley, B. G. and Clark, W. A. (1954).
Simulation of self-organizing systems by digital computer.
IRE Transactions on Information Theory, 4:76--84.
- Feldbaum, 1960
-
Feldbaum, A. A. (1960).
Optimal Control Theory.
Academic Press, New York.
- Friston et al., 1994
-
Friston, K. J., Tononi, G., Reeke, G. N., Sporns, O., and Edelman, G. M.
(1994).
Value-dependent selection in the brain: Simulation in a synthetic
neural model.
Neuroscience, 59:229--243.
- Fu, 1970
-
Fu, K. S. (1970).
Learning control systems---Review and outlook.
IEEE Transactions on Automatic Control, pages 210--221.
- Galanter and Gerstenhaber, 1956
-
Galanter, E. and Gerstenhaber, M. (1956).
On thought: The extrinsic theory.
Psychological Review, 63:218--227.
- Gällmo and Asplund, 1995
-
Gällmo, O. and Asplund, H. (1995).
Reinforcement learning by construction of hypothetical targets.
In Alspector, J., Goodman, R., and Brown, T. X., editors,
Proceedings of the International Workshop on Applications of Neural Networks
to Telecommunications 2 (IWANNT-2), pages 300--307. Stockholm, Sweden.
- Gardner, 1981
-
Gardner (1981).
Samuel's checkers player.
In Barr, A. and Feigenbaum, E. A., editors, The Handbook of
Artificial Intelligence, I, pages 84--108. William Kaufmann, Los Altos,
CA.
- Gardner, 1973
-
Gardner, M. (1973).
Mathematical games.
Scientific American, 228:108.
- Gelperin et al., 1985
-
Gelperin, A., Hopfield, J. J., and Tank, D. W. (1985).
The logic of limax learning.
In Selverston, A., editor, Model Neural Networks and Behavior.
Plenum Press, New York.
- Gittins and Jones, 1974
-
Gittins, J. C. and Jones, D. M. (1974).
A dynamic allocation index for the sequential design of experiments.
Progress in Statistics, pages 241--266.
- Goldberg, 1989
-
Goldberg, D. E. (1989).
Genetic Algorithms in Search, Optimization, and Machine
Learning.
Addison-Wesley, Reading, MA.
- Goldstein, 1957
-
Goldstein, H. (1957).
Classical Mechanics.
Addison-Wesley, Rreadin, MA.
- Goodwin and Sin, 1984
-
Goodwin, G. C. and Sin, K. S. (1984).
Adaptive Filtering Prediction and Control.
Prentice-Hall, Englewood Cliffs, N.J.
- Gordon, 1995
-
Gordon, G. J. (1995).
Stable function approximation in dynamic programming.
In Prieditis, A. and Russell, S., editors, Proceedings of the
Twelfth International Conference on Machine Learning, pages 261--268, San
Francisco, CA. Morgan Kaufmann.
An expanded version was published as Technical Report CMU-CS-95-103,
Carnegie Mellon University, Pittsburgh, PA, 1995.
- Gordon, 1996
-
Gordon, G. J. (1996).
Stable fitted reinforcement learning.
In D. S. Touretzky, M. C. Mozer, M. E. H., editor, Advances in
Neural Information Processing Systems: Proceedings of the 1995 Conference,
pages 1052--1058, Cambridge, MA. MIT Press.
- Griffith, 1966
-
Griffith, A. K. (1966).
A new machine learning technique applied to the game of checkers.
Technical Report Project MAC Artificial Intelligence Memo 94,
Massachusetts Institute of Technology.
- Griffith, 1974
-
Griffith, A. K. (1974).
A comparison and evaluation of three machine learning procedures as
applied to the game of checkers.
Artificial Intelligence, 5:137--148.
- Gullapalli, 1990
-
Gullapalli, V. (1990).
A stochastic reinforcement algorithm for learning real-valued
functions.
Neural Networks, 3:671--692.
- Gurvits et al., 1994
-
Gurvits, L., Lin, L.-J., and Hanson, S. J. (1994).
Incremental learning of evaluation functions for absorbing Markov
chains: New methods and theorems.
Preprint.
- Hampson, 1983
-
Hampson, S. E. (1983).
A Neural Model of Adaptive Behavior.
PhD thesis, University of California, Irvine, CA.
- Hampson, 1989
-
Hampson, S. E. (1989).
Connectionist Problem Solving: Computational Aspects of
Biological Learning.
Birkhauser, Boston.
- Hawkins and Kandel, 1984
-
Hawkins, R. D. and Kandel, E. R. (1984).
Is there a cell-biological alphabet for simple forms of learning?
Psychological Review, 91:375--391.
- Hersh and Griego, 1969
-
Hersh, R. and Griego, R. J. (1969).
Brownian motion and potential theory.
Scientific American, pages 66--74.
- Hilgard and Bower, 1975
-
Hilgard, E. R. and Bower, G. H. (1975).
Theories of Learning.
Prentice-Hall, Englewood Cliffs, NJ.
- Hinton, 1984
-
Hinton, G. E. (1984).
Distributed representations.
Technical Report CMU-CS-84-157, Department of Computer Science,
Carnegie-Mellon University, Pittsburgh, PA.
- Hochreiter and Schmidhuber, 1997
-
Hochreiter, S. and Schmidhuber, J. (1997).
Long short-term memory.
Neural Computation.
- Holland, 1975
-
Holland, J. H. (1975).
Adaptation in Natural and Artificial Systems.
University of Michigan Press, Ann Arbor.
- Holland, 1976
-
Holland, J. H. (1976).
Adaptation.
In Rosen, R. and Snell, F. M., editors, Progress in Theoretical
Biology, volume 4, pages 263--293. Academic Press, NY.
- Holland, 1986
-
Holland, J. H. (1986).
Escaping brittleness: The possibility of general-purpose learning
algorithms applied to rule-based systems.
In Michalski, R. S., Carbonell, J. G., and Mitchell, T. M., editors,
Machine Learning: An Artificial Intelligence Approach, Volume II,
pages 593--623. Morgan Kaufmann, San Mateo, CA.
- Houk et al., 1995
-
Houk, J. C., Adams, J. L., and Barto, A. G. (1995).
A model of how the basal ganglia generates and uses neural signals
that predict reinforcement.
In Houk, J. C., Davis, J. L., and Beiser, D. G., editors, Models
of Information Processing in the Basal Ganglia, pages 249--270. MIT Press,
Cambridge, MA.
- Howard, 1960
-
Howard, R. (1960).
Dynamic Programming and Markov Processes.
MIT Press, Cambridge, MA.
- Hull, 1943
-
Hull, C. L. (1943).
Principles of Behavior.
D. Appleton-Century, NY.
- Hull, 1952
-
Hull, C. L. (1952).
A Behavior System.
Wiley, NY.
- Jaakkola et al., 1994
-
Jaakkola, T., Jordan, M. I., and Singh, S. P. (1994).
On the convergence of stochastic iterative dynamic programming
algorithms.
Neural Computation, 6.
- Jaakkola et al., 1995
-
Jaakkola, T., Singh, S. P., and Jordan, M. I. (1995).
Reinforcement learning algorithm for partially observable Markov
decision problems.
In G. Tesauro, D. Touretzky, T. L., editor, Advances in Neural
Information Processing Systems: Proceedings of the 1994 Conference, pages
345--352, San Mateo, CA. Morgan Kaufmann.
- Kaelbling, 1996
-
Kaelbling (1996).
A special issue of machine learning on reinforcement learning.
22.
- Kaelbling, 1993a
-
Kaelbling, L. (1993a).
Hierarchical learning in stochastic domains: Preliminary results.
In Proceedings of the Tenth International Conference on Machine
Learning, pages 167--173. Morgan Kaufmann.
- Kaelbling, 1993b
-
Kaelbling, L. P. (1993b).
Learning in Embedded Systems.
MIT Press, Cambridge MA.
- Kaelbling et al., 1996
-
Kaelbling, L. P., Littman, M. L., and Moore, A. W. (1996).
Reinforcement learning: A survey.
Journal of Artificial Intelligence Research, 4.
- Kakutani, 1945
-
Kakutani, S. (1945).
Markov processes and the dirichlet problem.
Proc. Jap. Acad., 21:227--233.
- Kalos and Whitlock, 1986
-
Kalos, M. H. and Whitlock, P. A. (1986).
Monte Carlo Methods.
Wiley, NY.
- Kanerva, 1988
-
Kanerva, P. (1988).
Sparse Distributed Memory.
MIT Press, Cambridge, MA.
- Kanerva, 1993
-
Kanerva, P. (1993).
Sparse distributed memory and related models.
In Hassoun, M. H., editor, Associative Neural Memories: Theory
and Implementation, pages 50--76. Oxford University Press, NY.
- Kashyap et al., 1970
-
Kashyap, R. L., Blaydon, C. C., and Fu, K. S. (1970).
Stochastic approximation.
In Mendel, J. M. and Fu, K. S., editors, Adaptive, Learning, and
Pattern Recognition Systems: Theory and Applications. Academic Press, New
York.
- Keerthi and Ravindran, 1997
-
Keerthi, S. S. and Ravindran, B. (1997).
Reinforcement learning.
In Fiesler, E. and Beale, R., editors, Handbook of Neural
Computation. Oxford University Press, USA.
- Kimble, 1961
-
Kimble, G. A. (1961).
Hilgard and Marquis' Contitioning and Learning.
Appleton-Century-Crofts, Inc., New York.
- Kimble, 1967
-
Kimble, G. A. (1967).
Foundations of Conditioning and Learning.
Appleton-Century-Crofts.
- Kirkpatrick et al., 1983
-
Kirkpatrick, S., Gelatt, C. D., and Vecchi, M. P. (1983).
Optimization by simulated annealing.
Science, 220:671--680.
- Klopf, 1972
-
Klopf, A. H. (1972).
Brain function and adaptive systems---A heterostatic theory.
Technical Report AFCRL-72-0164, Air Force Cambridge Research
Laboratories, Bedford, MA.
A summary appears in Proceedings of the International Conference
on Systems, Man, and Cybernetics, 1974, IEEE Systems, Man, and Cybernetics
Society, Dallas, TX.
- Klopf, 1975
-
Klopf, A. H. (1975).
A comparison of natural and artificial intelligence.
SIGART Newsletter, 53:11--13.
- Klopf, 1982
-
Klopf, A. H. (1982).
The Hedonistic Neuron: A Theory of Memory, Learning, and
Intelligence.
Hemisphere, Washington, D.C.
- Klopf, 1988
-
Klopf, A. H. (1988).
A neuronal model of classical conditioning.
Psychobiology, 16:85--125.
- Kohonen, 1977
-
Kohonen, T. (1977).
Associative Memory: A System Theoretic Approach.
Springer-Varlag, Berlin.
- Korf, 1988
-
Korf, R. E. (1988).
Optimal path finding algorithms.
In Kanal, L. N. and Kumar, V., editors, Search in Artificial
Intelligence, pages 223--267. Springer Verlag, Berlin.
- Kraft and Campagna, 1990
-
Kraft, L. G. and Campagna, D. P. (1990).
A summary comparison of CMAC neural network and traditional
adaptive control systems.
In Miller, T., Sutton, R. S., and Werbos, P. J., editors, Neural
Networks for Control, pages 143--169. MIT Press, Cambridge, MA.
- Kraft et al., 1992
-
Kraft, L. G., Miller, W. T., and Dietz, D. (1992).
Development and application of CMAC neural network-based control.
In White, D. A. and Sofge, D. A., editors, Handbook of
Intelligent Control: Neural, Fuzzy, and Adaptive Approaches, pages 215--232.
Van Nostrand Reinhold, New York.
- Kuman and Varaiya, 1986
-
Kuman, P. R. and Varaiya, P. (1986).
Stochastic Systems: Estimation, Identification, and Adaptive
Control.
Prentice-Hall, Englewood Cliffs, NJ.
- Kumar, 1985
-
Kumar, P. R. (1985).
A survey of some results in stochastic adaptive control.
SIAM Journal of Control and Optimization, 23:329--380.
- Kumar and Kanal, 1988
-
Kumar, V. and Kanal, L. N. (1988).
The CDP: A unifying formulation for heuristic search, dynamic
programming, and branch-and-bound.
In Kanal, L. N. and Kumar, V., editors, Search in Artificial
Intelligence, pages 1--37. Springer-Verlag.
- Kushner and Dupuis, 1992
-
Kushner, H. J. and Dupuis, P. (1992).
Numerical Methods for Stochastic Control Problems in Continuous
Time.
Springer-Verlag, New York.
- Lai, 1987
-
Lai, T. L. (1987).
Adaptive treatment allocation and the multi-armed bandit problem.
The Annals of Statistics, 15(3):1091--1114.
- Lang et al., 1990
-
Lang, K. J., Waibel, A. H., and Hinton, G. E. (1990).
A time-delay neural network architecture for isolated word
recognition.
Neural Networks, 3:33--43.
- Lin and Kim, 1991
-
Lin, C.-S. and Kim, H. (1991).
Cmac-based adaptive critic self-learning control.
IEEE Transactions on Neural Networks, 2:530--533.
- Lin, 1992
-
Lin, L.-J. (1992).
Self-improving reactive agents based on reinforcement learning,
planning and teaching.
Machine Learning, 8:293--321.
- Lin and Mitchell, 1992
-
Lin, L.-J. and Mitchell, T. (1992).
Reinforcement learning with hidden states.
In Proceedings of the Second International Conference on
Simulation of Adaptive Behavior: From Animals to Animats, pages 271--280.
MIT Press.
- Littman, 1994
-
Littman, M. L. (1994).
Markov games as a framework for multi-agent reinforcement learning.
In Proceedings of the Eleventh International Conference on
Machine Learning, pages 157--163, San Francisco, CA. Morgan Kaufmann.
- Littman et al., 1995a
-
Littman, M. L., Cassandra, A. R., and Kaelbling, L. P. (1995a).
Learning policies for partially observable environments: Scaling
up.
In Prieditis, A. and Russell, S., editors, Proceedings of the
Twelfth International Conference on Machine Learning, pages 362--370, San
Francisco, CA. Morgan Kaufmann.
- Littman et al., 1995b
-
Littman, M. L., Dean, T. L., and Kaelbling, L. P. (1995b).
On the complexity of solving Markov decision processes.
In Proceedings of the Eleventh International Conference on
Uncertainty in Artificial Intelligence.
- Ljung and Söderstrom, 1983
-
Ljung, L. and Söderstrom, T. (1983).
Theory and Practice of Recursive Identification.
MIT Press, Cambridge, MA.
- Lovejoy, 1991
-
Lovejoy, W. S. (1991).
A survey of algorithmic methods for partially observed Markov
decision processes.
Annals of Operations Research, 28:47--66.
- Luce, 1959
-
Luce, D. (1959).
Individual Choice Behavior.
Wiley, NY.
- M. Zweben, 1994
-
M. Zweben, B. Daun, M. D. (1994).
Scheduling and rescheduling with iterative repair.
In Zweben, M. and Fox, M. S., editors, Intelligent Scheduling,
pages 241--255. Morgan Kaufmann, San Francisco, CA.
- Maclin and Shavlik, 1994
-
Maclin, R. and Shavlik, J. W. (1994).
Incorporating advice into agents that learn from reinforcements.
In Proceedings of the Twelfth National Conference on Artificial
Intelligence (AAAI-94).
- Mahadevan, 1996
-
Mahadevan, S. (1996).
Average reward reinforcement learning: Foundations, algorithms, and
empirical results.
Machine Learning, 22:159--196.
- Markey, 1994
-
Markey, K. L. (1994).
Efficient learning of multiple degree-of-freedom control problems
with quasi-independent q-agents.
In Mozer, M. C., Smolensky, P., Touretzky, D. S., Elman, J. L., and
Weigend, A. S., editors, Proceedings of the 1009 Connectionist Models
Summer School, Hillsdale, NJ. Erlbaum.
- Mazur, 1994
-
Mazur, J. E. (1994).
Learning and Behavior, Third Edition.
Prentice-Hall, Englewood Cliffs, NJ.
- McCallum, 1992
-
McCallum, A. K. (1992).
Reinforcement learning with perceptual aliasing: The perceptual
distinctions approach.
In Proceedings of the Tenth National Conference on Artificial
Intelligence, pages 183--188, Menlo Park, CA. AAAI Press/MIT Press.
- McCallum, 1993
-
McCallum, A. K. (1993).
Overcoming incomplete perception with utile distinction memory.
In Proceedings of the Tenth International Conference on Machine
Learning, pages 190--196. Morgan Kaufmann.
- McCallum, 1995
-
McCallum, A. K. (1995).
Reinforcement Learning with Selective Perception and Hidden
State.
PhD thesis, University of Rochester, Rochester.
- Mendel, 1966
-
Mendel, J. M. (1966).
Applications of artificial intelligence techniques to a spacecraft
control problem.
Technical Report NASA CR-755, National Aeronautics and Space
Administration.
- Mendel and McLaren, 1970
-
Mendel, J. M. and McLaren, R. W. (1970).
Reinforcement learning control and pattern recognition systems.
In Mendel, J. M. and Fu, K. S., editors, Adaptive, Learning and
Pattern Recognition Systems: Theory and Applications, pages 287--318.
Academic Press, New York.
- Michie, 1961
-
Michie, D. (1961).
Trial and error.
In Barnett, S. A. and McLaren, A., editors, Science Survey, Part
2, pages 129--145, Harmondsworth. Penguin.
- Michie, 1963
-
Michie, D. (1963).
Experiments on the mechanisation of game learning. 1.
characterization of the model and its parameters.
Computer Journal, 1:232--263.
- Michie, 1974
-
Michie, D. (1974).
On Machine Intelligence.
Edinburgh University Press.
- Michie and Chambers, 1968
-
Michie, D. and Chambers, R. A. (1968).
BOXES: An experiment in adaptive control.
In Dale, E. and Michie, D., editors, Machine Intelligence 2,
pages 137--152. Oliver and Boyd.
- Miller and Williams, 1992
-
Miller, S. and Williams, R. J. (1992).
Learning to control a bioreactor using a neural net dyna-q system.
In Proceedings of the Seventh Yale Workshop on Adaptive and
Learning Systems, pages 167--172, Center for Systems Science, Dunham
Laboratory, Yale University.
- Miller et al., 1994
-
Miller, W. T., Scalera, S. M., and Kim, A. (1994).
Neural network control of dynamic balance for a biped walking robot.
In Proceedings of the Eighth Yale Workshop on Adaptive and
Learning Systems, pages 156--161, Dunham Laboratory, Yale University. Center
for Systems Science.
- Minsky, 1954
-
Minsky, M. L. (1954).
Theory of Neural-Analog Reinforcement Systems and its
Application to the Brain-Model Problem.
PhD thesis, Princeton University.
- Minsky, 1961
-
Minsky, M. L. (1961).
Steps toward artificial intelligence.
Proceedings of the Institute of Radio Engineers, 49:8--30.
Reprinted in E. A. Feigenbaum and J. Feldman, editors, Computers
and Thought. McGraw-Hill, New York, 406--450, 1963.
- Minsky, 1967
-
Minsky, M. L. (1967).
Computation: Finite and Infinite Machines.
Prentice Hall, Englewood Cliffs, NJ.
- Montague et al., 1996
-
Montague, P. R., Dayan, P., and Sejnowski, T. J. (1996).
A framework for mesencephalic dopamine systems based on predictive
hebbian learning.
Journal of Neuroscience, 16:1936--1947.
- Moore, 1990
-
Moore, A. W. (1990).
Efficient Memory-Based Learning for Robot Control.
PhD thesis, University of Cambridge, Cambridge, UK.
- Moore, 1994
-
Moore, A. W. (1994).
The parti-game algorithm for variable resolution reinforcement
learning in multidimensional spaces.
In Cohen, J. D., Tesauro, G., and Alspector, J., editors,
Advances in Neural Information Processing Systems: Proceedings of the 1993
Conference, pages 711--718, San Francisco, CA. Morgan Kaufmann.
- Moore and Atkeson, 1993
-
Moore, A. W. and Atkeson, C. G. (1993).
Prioritized sweeping: Reinforcement learning with less data and
less real time.
Machine Learning, 13:103--130.
- Moore et al., 1986
-
Moore, J. W., Desmond, J. E., Berthier, N. E., Blazis, E. J., Sutton, R. S.,
and Barto, A. G. (1986).
Simulation of the classically conditioned nictitating membrane
response by a neuron-like adaptive element: I. Response topography,
neuronal firing, and interstimulus intervals.
Behavioural Brain Research, 21:143--154.
- Narendra and Thathachar, 1989
-
Narendra, K. and Thathachar, M. A. L. (1989).
Learning Automata: An Introduction.
Prentice Hall, Englewood Cliffs, NJ.
- Narendra and Thathachar, 1974
-
Narendra, K. S. and Thathachar, M. A. L. (1974).
Learning automata---A survey.
IEEE Transactions on Systems, Man, and Cybernetics, 4:323--334.
- Nie and Haykin, 1996
-
Nie, J. and Haykin, S. (1996).
A dynamic channel assignment policy through q-learning.
CRL Report 334, Hamilton, Ontario, Canada L8S 4K1.
- Page, 1977
-
Page, C. V. (1977).
Heuristics for signature table analysis as a pattern recognition
technique.
IEEE Transactions on Systems, Man, and Cybernetics,
SMC-7:77--86.
- Parr and Russell, 1995
-
Parr, R. and Russell, S. (1995).
Approximating optimal policies for partially observable stochastic
domains.
In Proceedings of the Fourteenth International Joint
Conference on Artificial Intelligence.
- Pavlov, 1927
-
Pavlov, P. I. (1927).
Conditioned Reflexes.
Oxford, London.
- Pearl, 1984
-
Pearl, J. (1984).
Heuristics: Intelligent Search Strategies for Computer Problem
Solving.
Addison-Wesley.
- Peng, 1993
-
Peng, J. (1993).
Efficient Dynamic Programming-Based Learning for Control.
PhD thesis, Northeastern University, Boston, MA.
- Peng and Williams, 1993
-
Peng, J. and Williams, R. J. (1993).
Efficient learning and planning within the Dyna framework.
Adaptive Behavior, 1(4).
- Peng and Williams, 1994
-
Peng, J. and Williams, R. J. (1994).
Incremental multi-step q-learning.
In Cohen, W. W. and Hirsh, H., editors, Proceedings of the
Eleventh International Conference on Machine Learning, pages 226--232.
- Peng and Williams, 1996
-
Peng, J. and Williams, R. J. (1996).
Incremental multi-step q-learning.
Machine Learning, 22(1/2/3).
- Phansalkar and Thathachar, 1995
-
Phansalkar, V. V. and Thathachar, M. A. L. (1995).
Local and global optimization algorithms for generalized learning
automata.
Neural Computation, 7:950--973.
- Poggio and Girosi, 1989
-
Poggio, T. and Girosi, F. (1989).
A theory of networks for approximation and learning.
A.I. Memo 1140, Artificial Intelligence Laboratory, Massachusetts
Institute of Technology.
- Poggio and Girosi, 1990
-
Poggio, T. and Girosi, F. (1990).
Regularization algorithms for learning that are equivalent to
multilayer networks.
Science, 247:978--982.
- Powell, 1987
-
Powell, M. J. D. (1987).
Radial basis functions for multivariate interpolation: A review.
In Mason, J. C. and Cox, M. G., editors, Algorithms for
Approximation. Clarendon Press, Oxford.
- Puterman, 1994
-
Puterman, M. L. (1994).
Markov Decision Problems.
Wiley, NY.
- Puterman and Shin, 1978
-
Puterman, M. L. and Shin, M. C. (1978).
Modified policy iteration algorithms for discounted Markov decision
problems.
Management Science, 24:1127--1137.
- Reetz, 1977
-
Reetz, D. (1977).
Approximate solutions of a discounted Markovian decision process.
Bonner Mathematische Schriften, vol 98: Dynamische Optimierung,
pages 77--92.
- Ring, 1994
-
Ring, M. B. (1994).
Continual Learning in Reinforcement Environments.
PhD thesis, University of Texas at Austin, Austin, Texas 78712.
- Rivest and Schapire, 1987
-
Rivest, R. L. and Schapire, R. E. (1987).
Diversity-based inference of finite automata.
In Proceedings of the Twenty-Eighth Annual Symposium on
Foundations of Computer Science, pages 78--87.
- Robbins, 1952
-
Robbins, H. (1952).
Some aspects of the sequential design of experiments.
Bulletin of the American Mathematical Society, 58:527--535.
- Robertie, 1992
-
Robertie, B. (1992).
Carbon versus silicon: Matching wits with TD-gammon.
Inside Backgammon, 2(2):14--22.
- Rosenblatt, 1961
-
Rosenblatt, F. (1961).
Principles of Neurodynamics: Perceptrons and the Theory of
Brain Mechanisms.
Spartan Books, 6411 Chillum Place N.W., Washington, D.C.
- Ross, 1983
-
Ross, S. (1983).
Introduction to Stochastic Dynamic Programming.
Academic Press, New York.
- Rubinstein, 1981
-
Rubinstein, R. Y. (1981).
Simulation and the Monte Carlo Method.
Wiley, NY.
- Rumelhart et al., 1986
-
Rumelhart, D. E., Hinton, G. E., and Williams, R. J. (1986).
Learning internal representations by error propagation.
In Rumelhart, D. E. and McClelland, J. L., editors, Parallel
Distributed Processing: Explorations in the Microstructure of Cognition,
vol.1: Foundations. Bradford Books/MIT Press, Cambridge, MA.
- Rummery, 1995
-
Rummery, G. A. (1995).
Problem Solving with Reinforcement Learning.
PhD thesis, Cambridge University.
- Rummery and Niranjan, 1994
-
Rummery, G. A. and Niranjan, M. (1994).
On-line q-learning using connectionist systems.
Technical Report CUED/F-INFENG/TR 166, Cambridge University
Engineering Department.
- Russell and Norvig, 1995
-
Russell, S. and Norvig, P. (1995).
Artificial Intelligence: A Modern Approach.
Prentice Hall, Englewood Cliffs, NJ.
- Rust, 1996
-
Rust, J. (1996).
Numerical dynamic programming in economics.
In Amman, H., Kendrick, D., and Rust, J., editors, Handbook of
Computational Economics, pages 614--722. Elsevier, Amsterdam.
- S. J. Bradtke, 1994
-
S. J. Bradtke, B. E. Ydstie, A. G. B. (1994).
Adaptive linear quadratic control using policy iteration.
In Proceedings of the American Control Conference.
- Samuel, 1959
-
Samuel, A. L. (1959).
Some studies in machine learning using the game of checkers.
IBM Journal on Research and Development, pages 210--229.
Reprinted in E. A. Feigenbaum and J. Feldman, editors, Computers
and Thought, McGraw-Hill, New York, 1963.
- Samuel, 1967
-
Samuel, A. L. (1967).
Some studies in machine learning using the game of checkers.
II---Recent progress.
IBM Journal on Research and Development, pages 601--617.
- Schultz and Melsa, 1967
-
Schultz, D. G. and Melsa, J. L. (1967).
State Functions and Linear Control Systems.
McGraw-Hill, New York.
- Schultz et al., 1997
-
Schultz, W., Dayan, P., and Montague, P. R. (1997).
A neural substrate of prediction and reward.
Science, 275:1593--1598.
- Schwartz, 1993
-
Schwartz, A. (1993).
A reinforcement learning method for maximizing undiscounted rewards.
In Proceedings of the Tenth International Conference on Machine
Learning, pages 298--305. Morgan Kaufmann.
- Schweitzer and Seidmann, 1985
-
Schweitzer, P. J. and Seidmann, A. (1985).
Generalized polynomial approximations in Markovian decision
processes.
Journal of Mathematical Analysis and Applications,
110:568--582.
- Selfridge et al., 1985
-
Selfridge, O. J., Sutton, R. S., and Barto, A. G. (1985).
Training and tracking in robotics.
In Joshi, A., editor, Proceedings of the Ninth International
Joint Conference of Artificial Intelligence, pages 670--672, San Mateo, CA.
Morgan Kaufmann.
- Shannon, 1950a
-
Shannon, C. E. (1950a).
A chess-playing machine.
Scientific American, 182:48--51.
- Shannon, 1950b
-
Shannon, C. E. (1950b).
Programming a computer for playing chess.
Philosophical Magazine, 41:256--275.
- Shewchuk and Dean, 1990
-
Shewchuk, J. and Dean, T. (1990).
Towards learning time-varying functions with high input
dimensionality.
In Proceedings of the Fifth IEEE International Symposium on
Intelligent Control, pages 383--388. IEEE.
- Singh, 1992a
-
Singh, S. P. (1992a).
Reinforcement learning with a hierarchy of abstract models.
In Proceedings of the Tenth National Conference on Artificial
Intelligence, pages 202--207, Menlo Park, CA. AAAI Press/MIT Press.
- Singh, 1992b
-
Singh, S. P. (1992b).
Scaling reinforcement learning algorithms by learning variable
temporal resolution models.
In Proceedings of the Ninth International Machine Learning
Conference, pages 406--415, San Mateo, CA. Morgan Kaufmann.
- Singh, 1993
-
Singh, S. P. (1993).
Learning to Solve Markovian Decision Processes.
PhD thesis, University of Massachusetts, Amherst.
Appeared as CMPSCI Technical Report 93-77.
- Singh and Bertsekas, 1997
-
Singh, S. P. and Bertsekas, D. (1997).
Reinforcement learning for dynamic channel allocation in cellular
telephone systems.
In Advances in Neural Information Processing Systems:
Proceedings of the 1996 Conference, Cambridge, MA. MIT Press.
- Singh et al., 1994
-
Singh, S. P., Jaakkola, T., and Jordan, M. I. (1994).
Learning without state-estimation in partially observable Markovian
decision problems.
In Cohen, W. W. and Hirsch, H., editors, Proceedings of the
Eleventh International Conference on Machine Learning, pages 284--292, San
Francisco, CA. Morgan Kaufmann.
- Singh et al., 1995
-
Singh, S. P., Jaakkola, T., and Jordan, M. I. (1995).
Reinforcement learing with soft state aggregation.
In G. Tesauro, D. Touretzky, T. L., editor, Advances in Neural
Information Processing Systems: Proceedings of the 1994 Conference, pages
359--368, Cambridge, MA. MIT Press.
- Singh and Sutton, 1996
-
Singh, S. P. and Sutton, R. S. (1996).
Reinforcement learning with replacing eligibility traces.
Machine Learning, 22:123--158.
- Sivarajan et al., 1990
-
Sivarajan, K. N., McEliece, R. J., and Ketchum, J. W. (1990).
Dynamic channel assignment in cellular radio.
In Proceedings of the 40th Vehicular Technology Conference,
pages 631--637.
- Skinner, 1938
-
Skinner, B. F. (1938).
The Behavior of Organisms.
Appleton-Century, NY.
- Sofge and White, 1992
-
Sofge, D. A. and White, D. A. (1992).
Applied learning: Optimal control for manufacturing.
In White, D. A. and Sofge, D. A., editors, Handbook of
Intelligent Control: Neural, Fuzzy, and Adaptive Approaches, pages 259--281.
Van Nostrand Reinhold, New York.
- Spong, 1994
-
Spong, M. W. (1994).
Swing up control of the acrobot.
In Proceedings of the 1994 IEEE Conference on Robotics and
Automation, San Diego, CA.
- Staddon, 1983
-
Staddon, J. E. R. (1983).
Adaptive Behavior and Learning.
Cambridge University Press, Cambridge.
- Sutton, 1978a
-
Sutton, R. S. (1978a).
Learning theory support for a single channel theory of the brain.
- Sutton, 1978b
-
Sutton, R. S. (1978b).
Single channel theory: A neuronal theory of learning.
Brain Theory Newsletter, 4:72--75.
- Sutton, 1978c
-
Sutton, R. S. (1978c).
A unified theory of expectation in classical and instrumental
conditioning.
- Sutton, 1984
-
Sutton, R. S. (1984).
Temporal Credit Assignment in Reinforcement Learning.
PhD thesis, University of Massachusetts, Amherst, MA.
- Sutton, 1988
-
Sutton, R. S. (1988).
Learning to predict by the method of temporal differences.
Machine Learning, 3:9--44.
- Sutton, 1990
-
Sutton, R. S. (1990).
Integrated architectures for learning, planning, and reacting based
on approximating dynamic programming.
In Proceedings of the Seventh International Conference on
Machine Learning, pages 216--224, San Mateo, CA. Morgan Kaufmann.
- Sutton, 1991a
-
Sutton, R. S. (1991a).
Dyna, an integrated architecture for learning, planning, and
reacting.
SIGART Bulletin, 2:160--163.
Also appeared in Working Notes of the 1991 AAAI Spring
Symposium, pages 151--155.
- Sutton, 1991b
-
Sutton, R. S. (1991b).
Planning by incremental dynamic programming.
In Birnbaum, L. A. and Collins, G. C., editors, Proceedings of
the Eighth International Workshop on Machine Learning, pages 353--357, San
Mateo, CA. Morgan Kaufmann.
- Sutton, 1992
-
Sutton, R. S., editor (1992).
A Special Issue of Machine Learning on Reinforcement Learning,
volume 8. Machine Learning.
Also published as Reinforcement Learnng, Kluwer Academic Press,
Boston, MA 1992.
- Sutton, 1995
-
Sutton, R. S. (1995).
TD models: Modeling the world at a mixture of time scales.
In Prieditis, A. and Russell, S., editors, Proceedings of the
Twelfth International Conference on Machine Learning, pages 531--539, San
Francisco, CA. Morgan Kaufmann.
- Sutton, 1996
-
Sutton, R. S. (1996).
Generalization in reinforcement learning: Successful examples using
sparse coarse coding.
In Touretzky, D. S., Mozer, M. C., and Hasselmo, M. E., editors,
Advances in Neural Information Processing Systems: Proceedings of the 1995
Conference, pages 1038--1044, Cambridge, MA. MIT Press.
- Sutton and Barto, 1981a
-
Sutton, R. S. and Barto, A. G. (1981a).
An adaptive network that constructs and uses an internal model of its
world.
Cognition and Brain Theory, 3:217--246.
- Sutton and Barto, 1981b
-
Sutton, R. S. and Barto, A. G. (1981b).
Toward a modern theory of adaptive networks: Expectation and
prediction.
Psychological Review, 88:135--170.
- Sutton and Barto, 1987
-
Sutton, R. S. and Barto, A. G. (1987).
A temporal-difference model of classical conditioning.
In Proceedings of the Ninth Annual Conference of the Cognitive
Science Society, Hillsdale, NJ. Erlbaum.
- Sutton and Barto, 1990
-
Sutton, R. S. and Barto, A. G. (1990).
Time-derivative models of pavlovian reinforcement.
In Gabriel, M. and Moore, J., editors, Learning and
Computational Neuroscience: Foundations of Adaptive Networks, pages
497--537. MIT Press, Cambridge, MA.
- Sutton and Pinette, 1985
-
Sutton, R. S. and Pinette, B. (1985).
The learning of world models by connectionist networks.
In Proceedings of the Seventh Annual Conference of the Cognitive
Science Society, Irvine, CA.
- Sutton and Singh, 1994
-
Sutton, R. S. and Singh, S. (1994).
On bias and step size in temporal-difference learning.
In Proceedings of the Eighth Yale Workshop on Adaptive and
Learning Systems, pages 91--96, New Haven, CT. Yale University.
- Tadepally and Ok, 1994
-
Tadepally, P. and Ok, D. (1994).
H-learning: A reinforcement learning method to optimize
undiscounted average reward.
Technical Report 94-30-01, Oregon State University.
- Tan, 1991
-
Tan, M. (1991).
Learning a cost-sensitive internal representation for reinforcement
learning.
In Birnbaum, L. A. and Collins, G. C., editors, Proceedings of
the Eighth International Workshop on Machine Learning, pages 358--362, San
Mateo, CA. Morgan Kaufmann.
- Tan, 1993
-
Tan, M. (1993).
Multi-agent reinforcement learning: Independent vs. cooperative
agents.
In Proceedings of the Tenth International Conference on Machine
Learning, pages 330--337. Morgan Kaufmann.
- Tesauro, 1986
-
Tesauro, G. J. (1986).
Simple neural models of classical conditioning.
Biological Cybernetics, 55:187--200.
- Tesauro, 1992
-
Tesauro, G. J. (1992).
Practical issues in temporal difference learning.
Machine Learning, 8:257--277.
- Tesauro, 1994
-
Tesauro, G. J. (1994).
TD--gammon, a self-teaching backgammon program, achieves
master-level play.
Neural Computation, 6(2):215--219.
- Tesauro, 1995
-
Tesauro, G. J. (1995).
Temporal difference learning and TD-Gammon.
Communications of the ACM, 38:58--68.
- Tesauro and Galperin, 1997
-
Tesauro, G. J. and Galperin, G. R. (1997).
On-line policy improvement using monte-carlo search.
In Advances in Neural Information Processing Systems:
Proceedings of the 1996 Conference, Cambridge, MA. MIT Press.
- Tham, 1994
-
Tham, C. K. (1994).
Modular On-Line Function Approximation for Scaling up
Reinforcement Learning.
PhD thesis, Cambridge University.
- Thathachar and Sastry, 1986
-
Thathachar, M. A. L. and Sastry, P. S. (1986).
Estimator algorithms for learning automata.
In Proceedings of the Platinum Jubilee Conference on Systems and
Signal Processing, Bengalore, India.
- Thathachar and Sastry, 1995
-
Thathachar, M. A. L. and Sastry, P. S. (1995).
A new approach to the design of reinforcement schemes for learning
automata.
IEEE Transactions on Systems, Man, and Cybernetics,
15:168--175.
- Thompson, 1933
-
Thompson, W. R. (1933).
On the likelihood that one unknown probability exceeds another in
view of the evidence of two samples.
Biometrika, 25:285--294.
- Thompson, 1934
-
Thompson, W. R. (1934).
On the theory of apportionment.
American Journal of Mathematics, 57:450--457.
- Thorndike, 1911
-
Thorndike, E. L. (1911).
Animal Intelligence.
Hafner, Darien, Conn.
- Thorp, 1966
-
Thorp, E. O. (1966).
Beat the Dealer: A Winning Strategy for the Game of
Twenty-One.
Random House, New York.
- Tolman, 1932
-
Tolman, E. C. (1932).
Purposive Behavior in Animals and Men.
Century, New York.
- Tsetlin, 1973
-
Tsetlin, M. L. (1973).
Automaton Theory and Modeling of Biological Systems.
Academic Press, New York.
- Tsitsiklis, 1994
-
Tsitsiklis, J. N. (1994).
Asynchronous stochastic approximation and q-learning.
Machine Learning, 16:185--202.
- Tsitsiklis and Van Roy, 1996
-
Tsitsiklis, J. N. and Van Roy, B. (1996).
Feature-based methods for large scale dynamic programming.
Machine Learning, 22:59--94.
- Tsitsiklis and Van Roy, 1997
-
Tsitsiklis, J. N. and Van Roy, B. (1997).
An analysis of temporal-difference learning with function
approximation.
IEEE Transactions on Automatic Control.
- Ungar, 1990
-
Ungar, L. H. (1990).
A bioreactor benchmark for adaptive network-based process control.
In Miller, W. T., Sutton, R. S., and Werbos, P. J., editors,
Neural Networks for Control, pages 387--402. MIT Press, Cambridge, MA.
- Varga, 1962
-
Varga, R. S. (1962).
Matrix Iterative Analysis.
Prentice-Hall, Englewood Cliffs, NJ.
- Waltz and Fu, 1965
-
Waltz, M. D. and Fu, K. S. (1965).
A heuristic approach to reinforcment learning control systems.
IEEE Transactions on Automatic Control, 10:390--398.
- Watkins, 1989
-
Watkins, C. J. C. H. (1989).
Learning from Delayed Rewards.
PhD thesis, Cambridge University, Cambridge, England.
- Watkins and Dayan, 1992
-
Watkins, C. J. C. H. and Dayan, P. (1992).
Q-learning.
Machine Learning, 8:279--292.
- Werbos, 1992
-
Werbos, P. (1992).
Approximate dynamic programming for real-time control and neural
modeling.
In White, D. A. and Sofge, D. A., editors, Handbook of
Intelligent Control: Neural, Fuzzy, and Adaptive Approaches, pages 493--525.
Van Nostrand Reinhold, New York.
- Werbos, 1977
-
Werbos, P. J. (1977).
Advanced forecasting methods for global crisis warning and models of
intelligence.
General Systems Yearbook, 22:25--38.
- Werbos, 1982
-
Werbos, P. J. (1982).
Applications of advances in nonlinear sensitivity analysis.
In Drenick, R. F. and Kosin, F., editors, System Modeling an
Optimization. Springer-Verlag.
Proceedings of the Tenth IFIP Conference, New York, 1981.
- Werbos, 1987
-
Werbos, P. J. (1987).
Building and understanding adaptive systems: A
statistical/numerical approach to factory automation and brain research.
IEEE Transactions on Systems, Man, and Cybernetics, pages
7--20.
- Werbos, 1988
-
Werbos, P. J. (1988).
Generalization of back propagation with applications to a recurrent
gas market model.
Neural Networks, 1:339--356.
- Werbos, 1989
-
Werbos, P. J. (1989).
Neural networks for control and system identification.
In Proceedings of the 28th Conference on Decision and Control,
pages 260--265, Tampa, Florida.
- Werbos, 1990
-
Werbos, P. J. (1990).
Consistency of HDP applied to simple reinforcement learning
problem.
Neural Networks, 3:179--189.
- White, 1969
-
White, D. J. (1969).
Dynamic Programming.
Holden-Day, San Francisco.
- White, 1985
-
White, D. J. (1985).
Real applications of Markov decision processes.
Interfaces, 15:73--83.
- White, 1988
-
White, D. J. (1988).
Further real applications of Markov decision processes.
Interfaces, 18:55--61.
- White, 1993
-
White, D. J. (1993).
A survey of applications of Markov decision processes.
Journal of the Operational Research Society, 44:1073--1096.
- Whitehead and Ballard, 1991
-
Whitehead, S. D. and Ballard, D. H. (1991).
Learning to perceive and act by trial and error.
Machine Learning, 7(1):45--83.
- Whitt, 1978
-
Whitt, W. (1978).
Approximations of dynamic programs I.
Mathematics of Operations Research, 3:231--243.
- Whittle, 1982
-
Whittle, P. (1982).
Optimization over Time, volume 1.
Wiley, NY.
- Whittle, 1983
-
Whittle, P. (1983).
Optimization over Time, volume 2.
Wiley, NY.
- Widrow et al., 1973
-
Widrow, B., Gupta, N. K., and Maitra, S. (1973).
Punish/reward: Learning with a critic in adaptive threshold
systems.
IEEE Transactions on Systems, Man, and Cybernetics, 5:455--465.
- Widrow and Hoff, 1960
-
Widrow, B. and Hoff, M. E. (1960).
Adaptive switching circuits.
In 1960 WESCON Convention Record Part IV, pages 96--104.
Reprinted in J. A. Anderson and E. Rosenfeld, Neurocomputing:
Foundations of Research, MIT Press, Cambridge, MA, 1988.
- Widrow and Smith, 1964
-
Widrow, B. and Smith, F. W. (1964).
Pattern-recognizing control systems.
In Computer and Information Sciences (COINS) Proceedings,
Washington, D.C. Spartan.
- Widrow and Stearns, 1985
-
Widrow, B. and Stearns, S. D. (1985).
Adaptive Signal Processing.
Prentice-Hall, Inc., Englewood Cliffs, N.J.
- Williams, 1986
-
Williams, R. J. (1986).
Reinforcement learning in connectionist networks: A mathematical
analysis.
Technical Report ICS 8605, Institute for Cognitive Science,
University of California at San Diego, La Jolla, CA.
- Williams, 1987
-
Williams, R. J. (1987).
Reinforcement-learning connectionist systems.
Technical Report NU-CCS-87-3, College of Computer Science,
Northeastern University, Boston, MA.
- Williams, 1988
-
Williams, R. J. (1988).
On the use of backpropagation in associative reinforcement learning.
In Proceedings of the IEEE International Conference on Neural
Networks, pages 263--270, San Diego, CA.
- Williams, 1992
-
Williams, R. J. (1992).
Simple statistical gradient-following algorithms for connectionist
reinforcement learning.
Machine Learning, 8:229--256.
- Williams and Baird, 1990
-
Williams, R. J. and Baird, L. C. (1990).
A mathematical analysis of actor-critic architectures for learning
optimal controls through incremental dynamic programming.
In Proceedings of the Sixth Yale Workshop on Adaptive and
Learning Systems, pages 96--101, New Haven, CT.
- Wilson, 1994
-
Wilson, S. W. (1994).
ZCS: A zeroth order classifier system.
Evolutionary Compuation, 2:1--18.
- Witten, 1976
-
Witten, I. H. (1976).
The apparent conflict between estimation and control---A survey of
the two-armed problem.
Journal of the Franklin Institute, 301:161--189.
- Witten, 1977
-
Witten, I. H. (1977).
An adaptive optimal controller for discrete-time Markov
environments.
Information and Control, 34:286--295.
- Witten and Corbin, 1973
-
Witten, I. H. and Corbin, M. J. (1973).
Human operators and automatic adaptive controllers: A comparative
study on a particular control task.
International Journal of Man-Machine Studies, 5:75--104.
- Yee et al., 1990
-
Yee, R. C., Saxena, S., Utgoff, P. E., and Barto, A. G. (1990).
Explaining temporal differences to create useful concepts for
evaluating states.
In Proceedings of the Eighth National Conference on Artificial
Intelligence, pages 882--888, Cambridge, MA.
- Young, 1984
-
Young, P. (1984).
Recursive Estimation and Time-Series Analysis.
Springer-Verlag.
- Zhang and Yum, 1989
-
Zhang, M. and Yum, T. P. (1989).
Comparisons of channel-assignment strategies in cellular mobile
telephone systems.
IEEE Transactions on Vehicular Technology, 38.
- Zhang, 1996
-
Zhang, W. (1996).
Reinforcement Learning for Job-shop Scheduling.
PhD thesis, Oregon State University.
Tech Report CS-96-30-1.
- Zhang and Dietterich, 1995
-
Zhang, W. and Dietterich, T. G. (1995).
A reinforcement learning approach to job-shop scheduling.
In Proceedings of the Fourteenth International Joint Conference
on Artificial Intelligence, pages 1114--1120.
- Zhang and Dietterich, 1996
-
Zhang, W. and Dietterich, T. G. (1996).
High-performance job-shop scheduling with a time--delay
TD
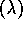 network.
In D. S. Touretzky, M. C. Mozer, M. E. H., editor, Advances in
Neural Information Processing Systems: Proceedings of the 1995 Conference,
pages 1024--1030, Cambridge, MA. MIT Press.
network.
In D. S. Touretzky, M. C. Mozer, M. E. H., editor, Advances in
Neural Information Processing Systems: Proceedings of the 1995 Conference,
pages 1024--1030, Cambridge, MA. MIT Press.
Richard Sutton
Fri May 30 21:03:54 EDT 1997