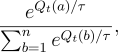Although ![]() -greedy action selection is an effective and popular means of
balancing exploration and exploitation in reinforcement learning, one
drawback is that when it explores it chooses equally among all
actions. This means that it is as likely to choose the worst-appearing
action as it is to choose the next-to-best action. In tasks where the worst
actions are very bad, this may be unsatisfactory. The obvious solution is to vary
the action probabilities as a graded function of estimated value. The greedy
action is still given the highest selection probability, but all the others are
ranked and weighted according to their value estimates. These are called softmax action selection rules. The most common softmax method uses a Gibbs,
or Boltzmann, distribution. It chooses action
-greedy action selection is an effective and popular means of
balancing exploration and exploitation in reinforcement learning, one
drawback is that when it explores it chooses equally among all
actions. This means that it is as likely to choose the worst-appearing
action as it is to choose the next-to-best action. In tasks where the worst
actions are very bad, this may be unsatisfactory. The obvious solution is to vary
the action probabilities as a graded function of estimated value. The greedy
action is still given the highest selection probability, but all the others are
ranked and weighted according to their value estimates. These are called softmax action selection rules. The most common softmax method uses a Gibbs,
or Boltzmann, distribution. It chooses action ![]() on the
on the ![]() th play with
probability
th play with
probability
Whether softmax action selection or ![]() -greedy action selection is better is
unclear and may depend on the task and on human factors. Both methods have only
one parameter that must be set. Most people find it easier to set the
-greedy action selection is better is
unclear and may depend on the task and on human factors. Both methods have only
one parameter that must be set. Most people find it easier to set the ![]() parameter with confidence; setting
parameter with confidence; setting ![]() requires knowledge of the likely action
values and of powers of
requires knowledge of the likely action
values and of powers of ![]() . We know of no careful comparative studies
of these two simple action-selection rules.
. We know of no careful comparative studies
of these two simple action-selection rules.
Exercise 2.2 (programming) How does the softmax action selection method using the Gibbs distribution fare on the 10-armed testbed? Implement the method and run it at several temperatures to produce graphs similar to those in Figure 2.1. To verify your code, first implement the
 Exercise 2.3
Show that in the case of two actions, the softmax operation using the Gibbs distribution
becomes the logistic, or sigmoid, function commonly used in artificial neural networks. What
effect does the temperature parameter have on the function?
Exercise 2.3
Show that in the case of two actions, the softmax operation using the Gibbs distribution
becomes the logistic, or sigmoid, function commonly used in artificial neural networks. What
effect does the temperature parameter have on the function?