


t discrete time step
T final time step of an episode
state at t
action at t
reward at t, dependent, like
, on
and
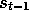
return (cumulative discounted reward) following t
n-step return (Section 7.1)

-return (Section 7.2)
policy
action taken in state s under deterministic policy

probability of taking action a in state s under stochastic policy

set of all nonterminal states
set of all states, includng the terminal state
set of actions possible in state s
probability of transition from state s to state
under action a
expected immediate reward on transition
under action a
value of state s under policy
(expected return)
value of state s under the optimal policy
V,
estimates of
or
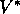
value of taking action a in state s under policy

value of taking action a in state s under the optimal policy
Q,
estimates of
or
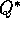
temporal-difference error at t
eligibility trace for state s at t
eligibility trace for a state-action pair
discount-rate parameter
step-size parameters
decay-rate parameterfor eligibility traces