The -return can be significantly generalized beyond what we have described so
far by allowing to vary from step to step, that is, by redefining the trace
update as
where denotes the value of at time . This is an advanced topic
because the added generality has never been used in practical applications,
but it is interesting theoretically and may yet prove useful. For example, one
idea is to vary as a function of state: . If a state's
value estimate is believed to be known with high certainty, then it makes sense to
use that estimate fully, ignoring whatever states and rewards are received after
it. This corresponds to cutting off all the traces once this state has been
reached, that is, to choosing the for the certain state to be zero or very
small. Similarly, states whose value estimates are highly uncertain, perhaps
because even the state estimate is unreliable, can be given s near 1.
This causes their estimated values to have little effect on any updates. They
are "skipped over" until a state that is known better is encountered. Some of
these ideas were explored formally by Sutton and Singh
(1994).
The eligibility trace equation above is the backward view of
variable s. The corresponding forward view is a
more general definition of the -return:
Exercise 7.10
Prove that the forward and backward views of off-line TD() remain
equivalent under their new definitions with variable given in this section.
Follow the example of the proof in Section 7.4.
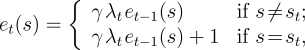
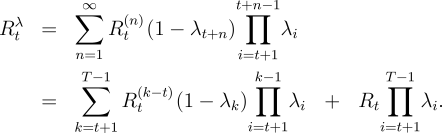
 Exercise 7.10
Prove that the forward and backward views of off-line TD(
Exercise 7.10
Prove that the forward and backward views of off-line TD(