


If one had to identify one idea as central and novel to reinforcement learning,
it would undoubtedly be temporal
difference (TD) learning. TD learning is a combination of Monte Carlo
ideas and dynamic programming (DP) ideas. Like Monte Carlo methods, TD methods can
learn directly from raw experience without a model of the environment's
dynamics. Like DP, TD methods update estimates based in part on other learned
estimates, without waiting for a final outcome (they bootstrap).
The relationship between TD, DP, and Monte Carlo methods is a recurring
theme in the theory of reinforcement learning. This
chapter is the beginning of our exploration of it. Before we
are done, we will see that these ideas and methods blend into each other and
can be combined in many ways. In particular, in Chapter 7 we
introduce the TD(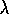 ) algorithm, which seamlessly integrates TD and Monte
Carlo methods.
) algorithm, which seamlessly integrates TD and Monte
Carlo methods.
As usual, we start by focusing on the policy-evaluation or prediction
problem, that of estimating the value function 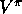 for a given policy
for a given policy  .
For the control problem (finding an optimal policy), all of DP, TD, and
Monte Carlo methods use some variation of generalized policy iteration (GPI). The
differences in the methods are primarily differences in their approaches to the
prediction problem.
.
For the control problem (finding an optimal policy), all of DP, TD, and
Monte Carlo methods use some variation of generalized policy iteration (GPI). The
differences in the methods are primarily differences in their approaches to the
prediction problem.