by Richard S. Sutton and Juan Carlos Santamaria
This document presents a standard interface for programming reinforcement learning simulations in Common Lisp. The Common Lisp implementation is based on CLOS, the Common Lisp Object System. There are three basic objects: agents, environments, and simulations. The agent is the learning agent and the environment is the task that it interacts with. The simulation manages the interaction between the agent and the environment, collects data, and manages the display, if any.
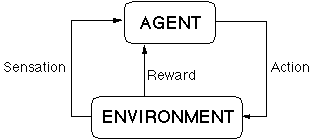
The outputs of the agent are termed actions, and the inputs of the agent are termed sensations. In the simplest case, the sensations are the states of the environment, but the interface allows them to be arbitrarily related to the true states of the environment. Here's the standard figure:
Whereas the reward is a number, the actions and sensations can be arbitrary lisp objects, as long as they are understood properly by the agent and the environment. Obviously the agent and environment have to be chosen to be compatible with each other in this way.
The interaction between the agent and environment is handled in discrete time. We assume we are working with simulations here; there are no real-time constraints enforced by the interface. In other words, the environment waits for the agent while the agent is selecting its action and the agent waits for the environment while the environment is computing its next state.
The interface supports either episodic (episode-based, finite horizon) or continuing (continually running, infinite horizon) tasks. Continuing tasks are treated as a single epsiode that never ends.
In a typical use of the interface, the user first defines
any needed specialized object classes and then creates her new
agent, environment, and simulation by calling
make-instance. All three objects are then passed
to sim-init which initializes and interconnects
them. Finally, calls to sim-steps (or
sim-episodes) actually run the simulation. Here is
a prototypical example:
A complete example including definitions of specific agent and environment classes is given in the final section of this document.(load "RLinterface.lisp") (use-package :RLI) ...somehow define my-agent-class and my-environment-class... (setq my-agent (make-instance 'my-agent-class)) (setq my-env (make-instance 'my-environment-class)) (setq my-sim (make-instance 'simulation)) (sim-init my-sim my-agent my-env) (sim-steps my-sim 10000000)
Note that all the documentation for all objects and routines includes HTML anchors to facilitate automatic indexing into this document. Links to the source code are also provided. For any lisp entity with a bracketed descriptor to its right (e.g., [function]), its source code can be brought up by clicking on the bracketed words. The complete source code is also available here.
The agent is the entity that interacts with the environment, that receives senations and selects actions. The agent may or may not learn, may or may not build a model of the environment, etc.
agent
The basic class of all agents. Specific agents are
instances of subclasses of agent.
(make-instance 'agent) creates a new instance of
agent. User defined agent classes (subclasses of
agent) will normally provide specialized
definitions of the following three functions.
This function is normally provided by the user for her
specialized agent class. (agent-init
agent) should initialize agent,
making any needed data-structures. If agent learns
or changes in any way with experience, then this function
should reset it to its original, naive condition. Normally,
agent-init is called once when the simulation is
first assembled and initialized. The default method for
agent-init does nothing.
If needed, the agent can consult with the environment or
the simulation as part of setting up its initialization
(although at present no standard interface has been defined
for this sort of interaction). The agent can access the
environment and simulation by calling agent-sim or agent-env. These environment and
simulation are both guaranteed to be existant and inited by
the time agent-init is called.
This function is usually provided by the user for her
specialized agent class. It is called at the beginning of each
new episode (in a continually running task, it will be called
once at the beginning of the simulation).
(agent-start-episode agent sensation)
should perform any needed initialization of agent
to prepare it for beginning a new episode. It should return the
first action of the agent in the new episode, in response to
sensation (the first sensation of the episode). A
typical definition for agent-start-episode is:
(defmethod agent-start-episode ((agent agent) sensation) (policy agent sensation))
where policy is a function or primary method
that implements the decision-making policy of the agent.
This is the main method for agent, where all
the learning takes place. It must be provided by the user and
will be called once on each step of
the simulation. (agent-step agent sensation reward) informs agent
that, in response to its previously
chosen action, the environment returned
sensation and reward.
The agent instance is responsible for
remembering the previous sensation and action in case it requires them for
learning. For this to work, agent-step must never be called directly by the
user. This method
returns the action to be taken in response to
sensation.
In a episodic task, sensation may take
on the special value :terminal-state, indicating
that the episode has terminated with this step. The author of
agent-step is responsible for checking for this
and adjusting its learning and other processes accordingly. In
this case, the value returned from agent-step
will be ignored.
The environment defines the problem to be solved. It determines the dynamics of the environment, the rewards, and the episode terminations.
environment
The basic class of all environments. Specific environments
are instances of subclasses of environment.
(make-instance 'environment) creates a new
instance of environment. User defined environment
classes (subclasses of environment) will normally
provide specialized definitions of the following three
functions.
This function is normally provided by the user for her
specialized environment class. (env-init
environment) should initialize
environment, making any needed data-structures. If
environment changes in any way with experience,
then this function should reset it to its original, naive
condition. Normally, env-init is called once when
the simulation is first assembled and initialized. The default
method for env-init does nothing.
If needed, the environment can consult with the simulation
as part of setting up its initialization. The environment can
access the simulation by calling env-sim. The corresponding agent is
not available at the time env-init is
called.
This function must be provided by the user for her
specialized environment class. It is normally called at the
beginning of each new episode (in a continually running task, it
will be called once at the beginning of the simulation).
(env-start-episode environment) should
perform any needed initialization of environment to
prepare it for beginning a new episode. It should return the
first sensation of the episode.
This is the main method for environment. It
must be provided by the user and will be called once on each
step of the simulation. (env-step environment
action) causes environment to undergo
a transition from its current state to a next state dependent
on action, generating a next sensation and a
reward, returned as two values.
If the transition is into a terminal state, then the next
sensation returned must have the special value
:terminal-state.
The simulation is the base object of the interface. It
manages the interaction between the agent and the environment.
The primary methods sim-init,
sim-steps and sim-episodes are
not intended to be changed by the user. They define
the heart of the interface, the uniform usage that all agents
and environments are meant to conform to.
Simulations can be specialized to provide reporting (see
sim-collect-data)
and display capabilities. For example, a display may start or
stop the simulation and show its progress in various ways.
Display updates can be triggered in
sim-collect-data, agent-step,
env-step , or whatever, by calling
user-provided methods associated with the specialized
simulation object (accessible via agent-sim or env-sim).
simulation
The basic class of all simulations. (make-instance
'simulation) creates a new instance of
simulation. Earlier
we saw a prototypical example of the use of a
simulation.
(sim-init simulation agent
environment) initializes simulation,
agent, and environment, which should be
objects of these classes. See the source code (by clicking on
the bracketed "primary method" above right) to see just how
this works.
(sim-start-episode simulation)
forces the beginning of a new episode in simulation.
This is done primarily by calls to
env-start-episode and
agent-start-episode. See the source code (by
clicking on the bracketed "primary method" above right) to see
exactly how this works.
Runs simulation for num-steps steps,
starting from whatever state the environment currently is in.
If the terminal state is reached, the simulation is
immediately prepared for a new episode by calling
sim-start-episode. The switch from the terminal
state to the new starting state does not count as a step.
See the source code
(by clicking on the bracketed "primary method" above right) to
see exactly how it works.
Runs simulation for num-episodes
episodes, each of which can be no longer than
max-steps-per-episode steps. Each episode begins by
calling sim-start-episode.
See the source code
(by clicking on the bracketed "primary method" above right) to
see exactly how it works.
This function is called once on each step of the simulation. The default method does nothing, but user-defined specialized methods might accumulate rewards or other data and update displays. This is the preferred way to gain access to the simulation's behavior.
The following routines are provided for accessing the three objects making up a simulation (agent, environment, and simulation) one from the other. Their names are all of the form a-b. They take as input an object of class a and return the associated object of class b:
sim-env simulationHere is code for a table-based agent using 1-step Q-learning for a particular finite MDP -- the maintenance task.